
How does the Groq's LPU work?
Each year, language models double in size and capabilities. To keep up, we need new specialized hardware architectures built from the ground up for AI workloads.

Artificial Intelligence is advancing at a blistering pace. One company delivering on that promise is Groq and their breakthrough Language Processing Unit (LPU). The LPU completely reimagines computing for machine learning, unlocking performance gains far beyond traditional GPUs.
The Language Processing Unit (LPU) is a custom inference engine developed by Groq, specifically optimized for large language models. As language models like Llama2, Phi 2, and Mistral etc… continue to rapidly grow in size, there is a need for specialized hardware that can provide fast and efficient inference. Groq's LPU aims to fill this need and delivers major performance improvements over traditional GPU-based solutions.
What is LPU (Language Processing Unit)?
LPU is a type of processor architecture designed specifically for tensor operations, a critical component of machine learning and artificial intelligence workloads. The LPU is a highly parallel, single-instruction, multiple-data (SIMD) processor that can execute thousands of operations simultaneously. This level of parallelism, combined with a highly optimized memory hierarchy, enables the LPU to deliver unprecedented performance and energy efficiency for AI and ML workloads.
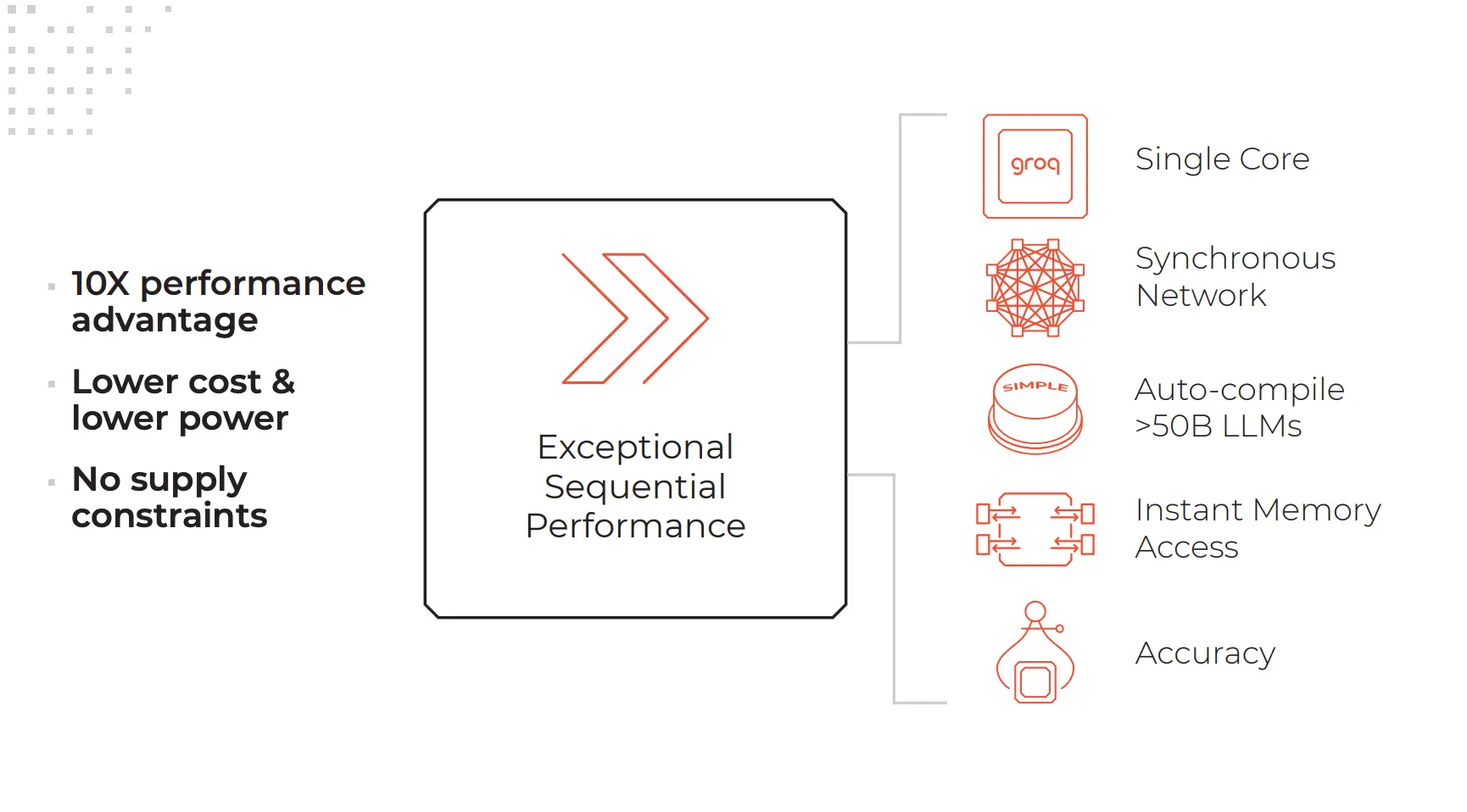
Features of LPU
- Tensor Streaming Core: The Tensor Streaming Core is the primary processing unit within the LPU and is responsible for executing tensor operations. It consists of thousands of processing elements (PEs) that can operate independently and in parallel. The Tensor Streaming Core supports various tensor operations, including matrix multiplication, convolution, and activation functions.
- Memory Hierarchy: An optimized memory hierarchy is crucial for high-performance tensor operations. The LPU features a multi-level memory hierarchy, including large on-chip SRAM, L2 cache, and off-chip DDR4 memory. This hierarchy ensures that data is readily available for the PEs, minimizing latency and maximizing throughput.
- Control Unit: The control unit manages the overall operation of the LPU, including instruction fetching, decoding, and scheduling. It also handles communication between the Tensor Streaming Core, memory hierarchy, and external interfaces.
- External Interfaces: The LPU includes high-speed interfaces, such as PCIe Gen4, CCIX, and Ethernet, enabling seamless integration with host systems and accelerator platforms.
 Anurag Vishwakarma
Anurag Vishwakarma
Why are GPUs Used to Train Large Language Models?
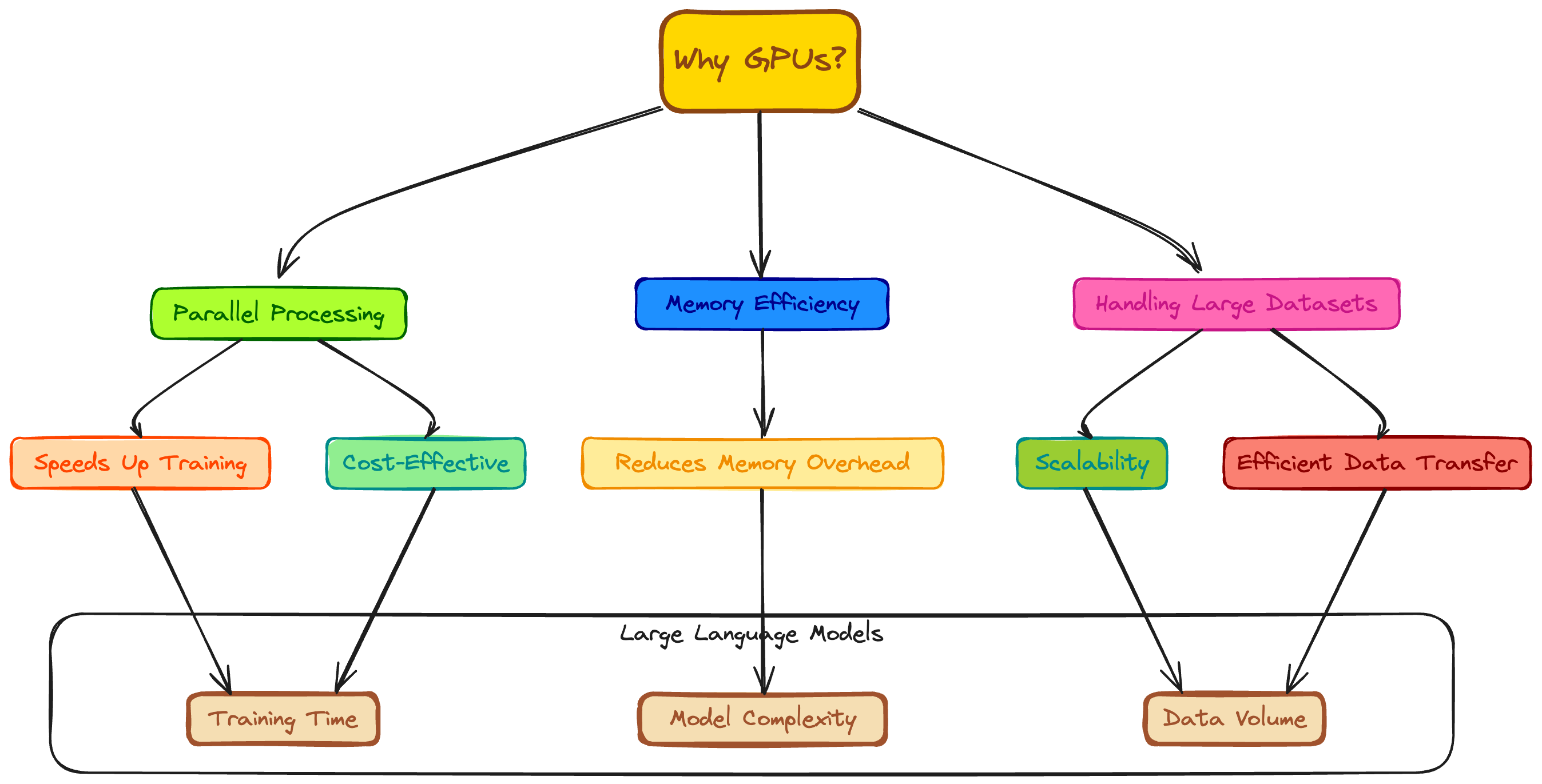
Training large language models requires massive amounts of computing power. GPUs are well-suited for this because they contain thousands of parallel cores that can process huge batches of data efficiently.
The matrix and vector operations involved in neural network training map well to the strengths of GPU architectures. With multiple high-bandwidth memories, GPUs can keep the cores fed with training data. The raw FLOPS capability from clusters of GPUs allows researchers to scale up language models to previously unfathomable sizes.
Anurag Vishwakarma
How does the Groq's LPU work?
Groq's engineers developed a Tensor Streaming Processor (TSP) that has been making waves in high-performance computing, artificial intelligence, and machine learning. At the heart of the TSP lies the Groq's Licensed Processing Unit (LPU), an innovative and highly efficient processor architecture that sets it apart from conventional CPUs and GPUs.
The LPU's operation is based on a single instruction, multiple data (SIMD) model, where thousands of PEs execute the same instruction on different data points simultaneously.
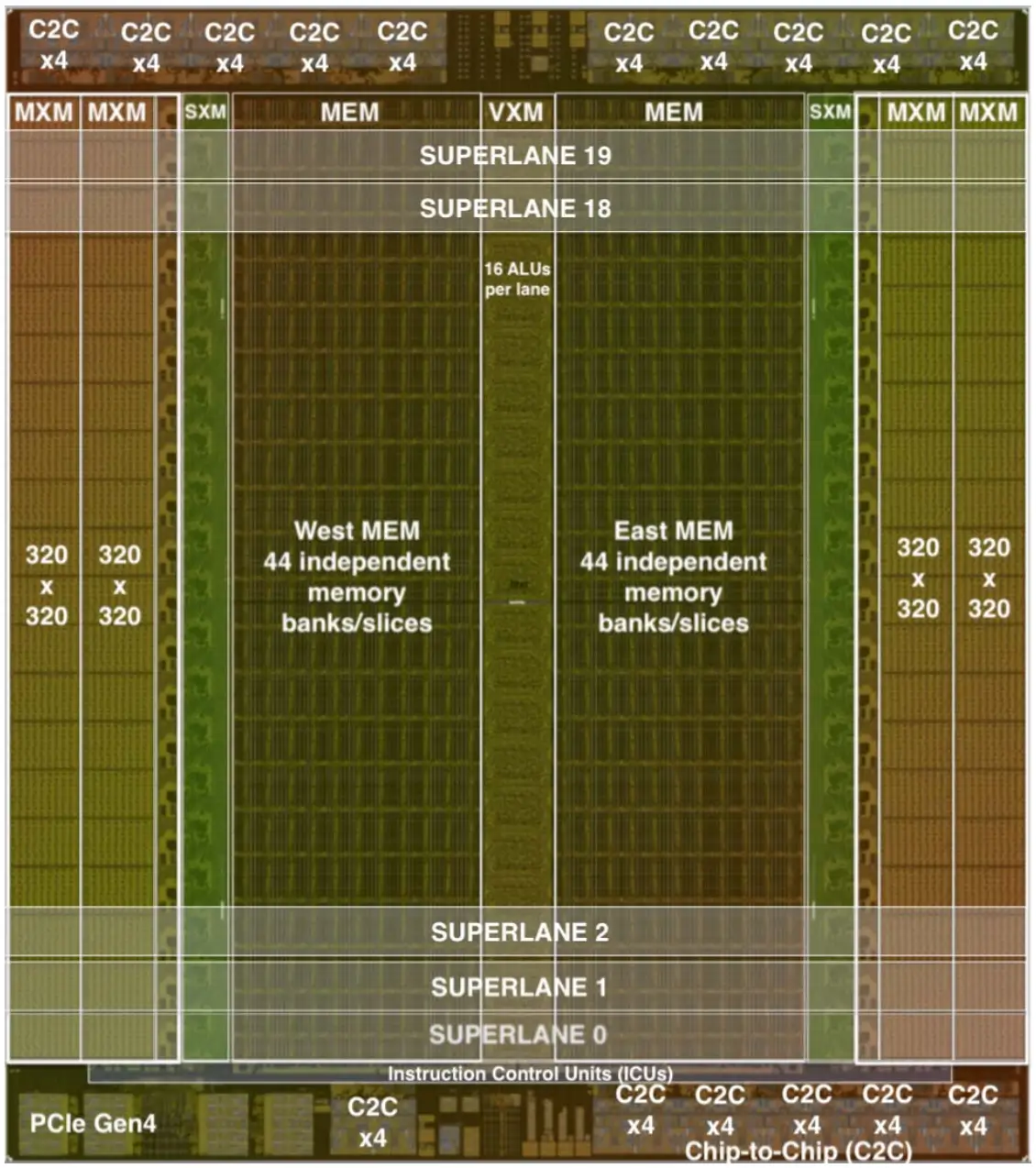
This parallelism is achieved through a combination of:
- Vector Processing: Each PE in the Tensor Streaming Core supports vector processing, enabling it to perform multiple operations on a single data point in a single clock cycle.
- Data Reuse: The LPU's memory hierarchy is designed to maximize data reuse, reducing the need for frequent memory accesses and minimizing energy consumption.
- Pipelining: The LPU employs pipelining to maximize throughput. Each stage of the pipeline is responsible for a specific task, allowing the LPU to process multiple operations concurrently.
- Instruction Scheduling: The control unit dynamically schedules instructions to optimize the use of PEs and memory resources, ensuring high utilization and minimal idle time.
The LPU chip is designed from the ground up to be fully deterministic. This means the hardware behaviour is completely predictable, unlike GPUs which have various caches and memory hierarchies. The LPU has a simple in-order architecture and the compiler software can schedule operations down to the nanosecond and clock cycle.
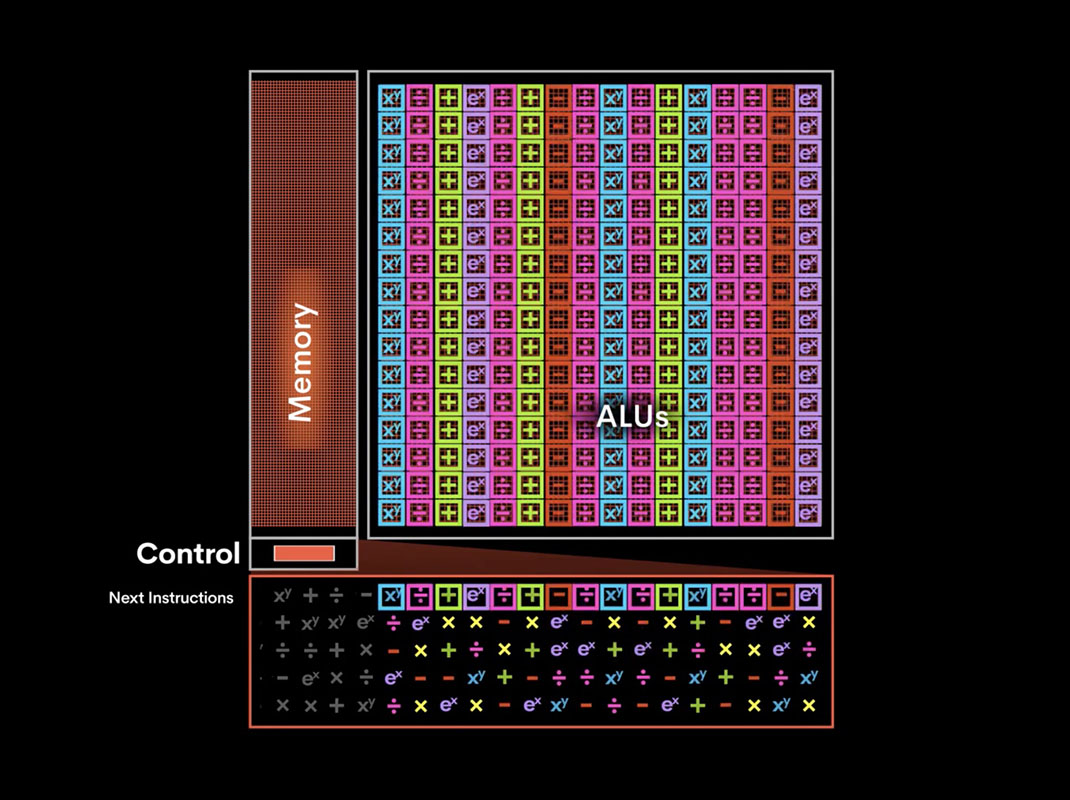
The LPU has direct access to on-chip memory with a bandwidth of up to 80TB/s. Rather than having multi-level caches, data movement is simplified with SRAM providing high bandwidth to compute units. The deterministic nature and software scheduling gives the compiler complete visibility and control over the hardware resources. It can precisely allocate computations to available functional units for maximum efficiency.
LPUs Follow Multi-Stage Natural Language Processing Pipeline:
- Tokenization: The input text is divided into smaller units called tokens, such as words, phrases, or characters. This step helps in organizing and understanding the structure of the text.
- Parsing: The tokens are analyzed to determine their grammatical structure and relationships. This process involves identifying parts of speech, dependencies, and syntactic patterns within the text.
- Semantic Analysis: The meaning of the text is inferred by analyzing the relationships between words and phrases. This stage involves tasks like named entity recognition, semantic role labelling, and coreference resolution.
- Feature Extraction: Relevant features, such as word embeddings, are extracted to represent the text in a numerical format that machine learning algorithms can process.
- Machine Learning Models: LPUs utilize various machine learning models, such as recurrent neural networks (RNNs), transformers, or deep neural networks (DNNs), to process and understand the language. These models are trained on large datasets to learn patterns and relationships in language.
- Inference and Prediction: LPUs use the trained models to make predictions or generate outputs based on the input text. This can include tasks like sentiment analysis, language translation, or text generation.
Anurag Vishwakarma
LPU System Architecture
To scale up to giant language models with billions of parameters, Groq synchronizes multiple LPU chips together into a deterministic network. The tight coupling provides low-latency access to large memory pools distributed across the system.

A unique advantage is the software-controlled network scheduling. Instead of individual hardware blocks making localized decisions, the system software has global knowledge across all chips. It can coordinate communications and computations down to the nanosecond, fully orchestrating data movement most optimally.
LPU vs GPU
While both leverage parallel processing, the LPU takes a very different approach compared to GPUs. The LPU is built for low-latency sequential workloads like inference. Its design allows the software to fully orchestrate operations across the system.
In contrast, GPUs rely on hardware mechanisms like caching and networking in an uncontrolled manner. This results in non-deterministic penalties that limit inference performance. The LPU delivers 10x better power efficiency and lower latency compared to GPUs.
Groq's LPU Performance Advantages
- 10x better power efficiency in joules per token
- Much lower overall latency from start to finish
- Strong scaling that maintains efficiency as the model size grows
Anurag Vishwakarma
Use Cases Beyond Language Models
While language model inference has been a killer application, the LPU accelerates many other workloads. In areas like drug discovery, cybersecurity, and finance, Groq has demonstrated 100x or greater speedups compared to GPU performance. The system is especially suited for low-latency applications needing complex sequential processing.

Applications of Groq's LPU
- Artificial Intelligence and Machine Learning: The LPU's highly parallel architecture and optimized memory hierarchy make it an ideal choice for AI and ML workloads, delivering unparalleled performance and energy efficiency.
- High-Performance Computing: The LPU's SIMD architecture and pipelining enable it to excel in high-performance computing applications, such as scientific simulations and data analytics.
- Networking and Communications: The LPU's high-speed interfaces and support for various network protocols make it suitable for networking and communication applications.
Upcoming Future of LPUs
The LPU architecture is just scratching the surface and constant innovation around deterministic systems provides a clear roadmap for orders of magnitude more performance gains.
Groq plans to enable custom LPU configurations tailored to specific workloads. Their design space exploration tool can quickly evaluate different chipset layouts, memory, compute, etc. to match customer requirements. This agile design cycle from software models to hardware deployment will keep the LPU on the cutting edge. Groq aims to stay far ahead of GPUs.
Conclusion
Groq's LPU represents a significant leap forward in processor architecture, designed explicitly for tensor operations and AI/ML workloads. Its innovative design, optimized memory hierarchy, and highly parallel architecture enable it to deliver unmatched performance and energy efficiency.
Through complete vertical stack optimization from software to silicon, it delivers on the promise of a specialized deterministic architecture. And this is only the beginning as Groq expects the LPU to rapidly advance and widen its performance lead over GPUs.
Research/Whitepaper -
Anurag Vishwakarma Anurag Vishwakarma
Anurag Vishwakarma Anurag Vishwakarma
Anurag Vishwakarma