
What is Vector Database and How does it work?
Vector databases are highly intriguing and offer numerous compelling applications, especially when it comes to providing extensive memory.
Recently, Vector databases have gained significant attention, with companies raising hundreds of millions of dollars to build them. Many consider them a revolutionary database for the AI era. However, while they are fascinating and offer numerous applications, they may not always be the optimal solution for every project. In some cases, a traditional database or even a numpy ND array could suffice.
Nonetheless, there's no denying that Vector databases are highly intriguing and offer numerous compelling applications, especially when it comes to providing extensive memory to large language models like GPT-4.
In this article, we will learn about vector databases. We will explain what they are and how they work. The first step to understand Vector Databases is to understand "Vector Embeddings".
A. What Are Vector Embeddings and Why Do We Need Them?
Embeddings are numerical representations of data that the computer can understand and compare.
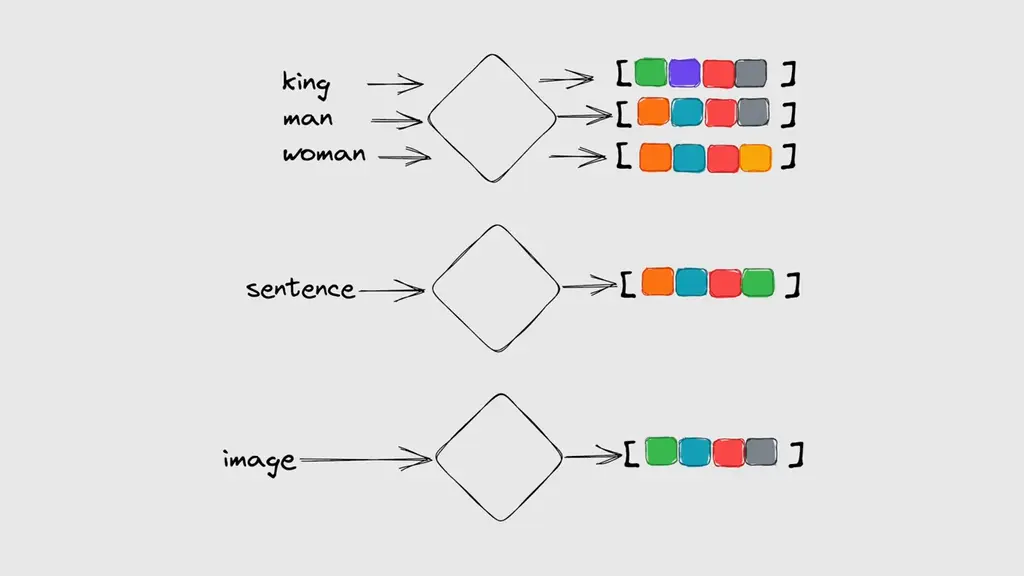
For example, we can convert text or images into vectors of numbers that capture their essential features. One advantage of using vectors is that we can measure their similarity by calculating their distances and performing a nearest neighbour search. This means that we can find the most similar items to a given query in a vector space.
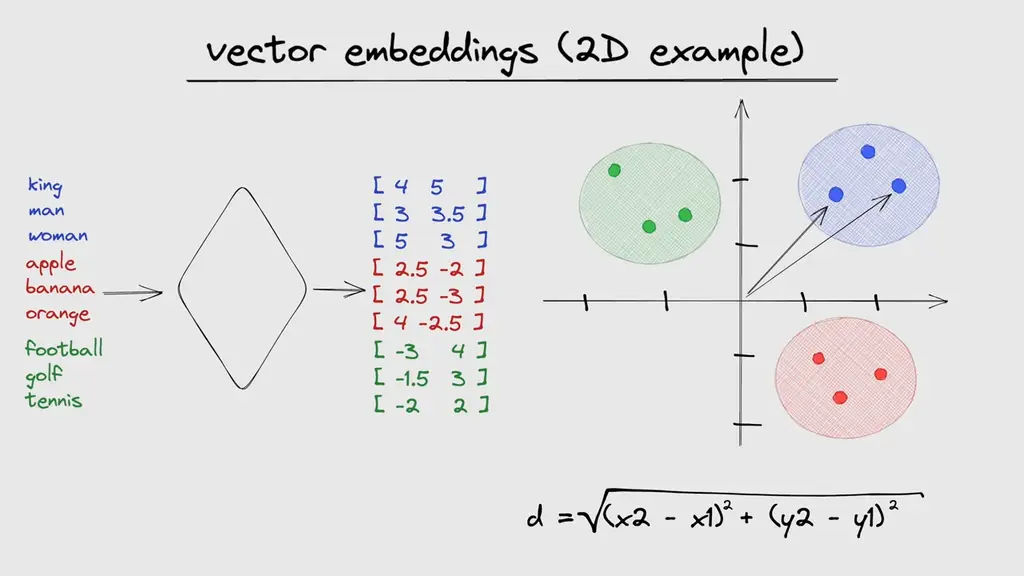
For simplicity, As you can see 2D case here, but in reality, those vectors can have hundreds of dimensions. But just storing the data as embeddings is not enough. Performing a query across thousands of vectors based on its distance metric would be extremely slow and inefficient.
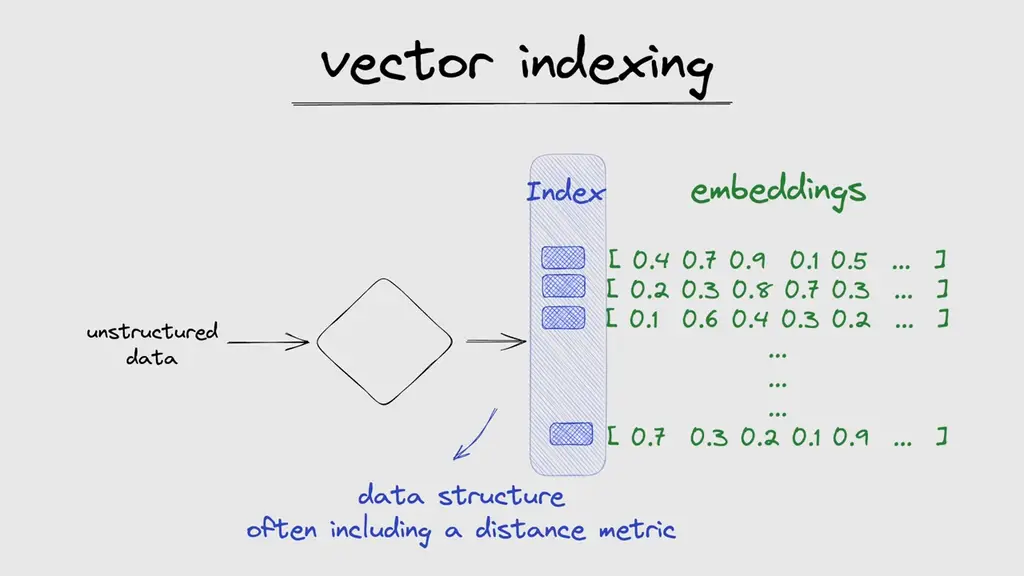
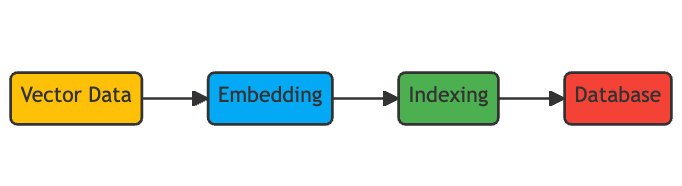
This is why those vectors also need to be indexed. An index is a data structure that facilitates the search process by mapping the vectors to a new data structure that will enable faster searching. This is a whole research field on its own and different ways to calculate indexes exist. Some of the most popular ones are locality-sensitive hashing (LSH), hierarchical navigable small world (HNSW), and inverted file index (IVF).
What is LSH, HNSW & IVF?
- LSH (Locality-Sensitive Hashing) is a way to put things that are alike in the same groups. It does this by giving them codes that are more likely to be the same.
- HNSW (Hierarchical Navigable Small World) is a way to link things that are alike. It does this by making different levels of links, with longer ones on top and shorter ones on bottom.
- IVF (Inverted File Index) is a way to store and find things. It does this by splitting them into smaller groups and using a table to remember where they are.
The main idea behind vector embeddings is to capture the semantic information of the data, such as its meaning, context, or similarity to other data points.
For example, if we have two sentences that have the same meaning but different words, such as "I like cats" and "I enjoy felines", we want their embeddings to be close to each other in the vector space.
Similarly, if we have two images that show the same object but from different angles or lighting conditions, we want their embeddings to be close to each other as well.
Vector embeddings are calculated by machine learning models, such as neural networks or transformers, that learn from large amounts of data. These models can map the data from its original format (such as pixels or words) to a high-dimensional vector space (such as 128-dimensional or 512-dimensional). The dimensionality of the vector space determines how much information can be encoded in the embedding. The higher the dimensionality, the more granular and precise the embedding can be.
 Anurag Vishwakarma
Anurag Vishwakarma
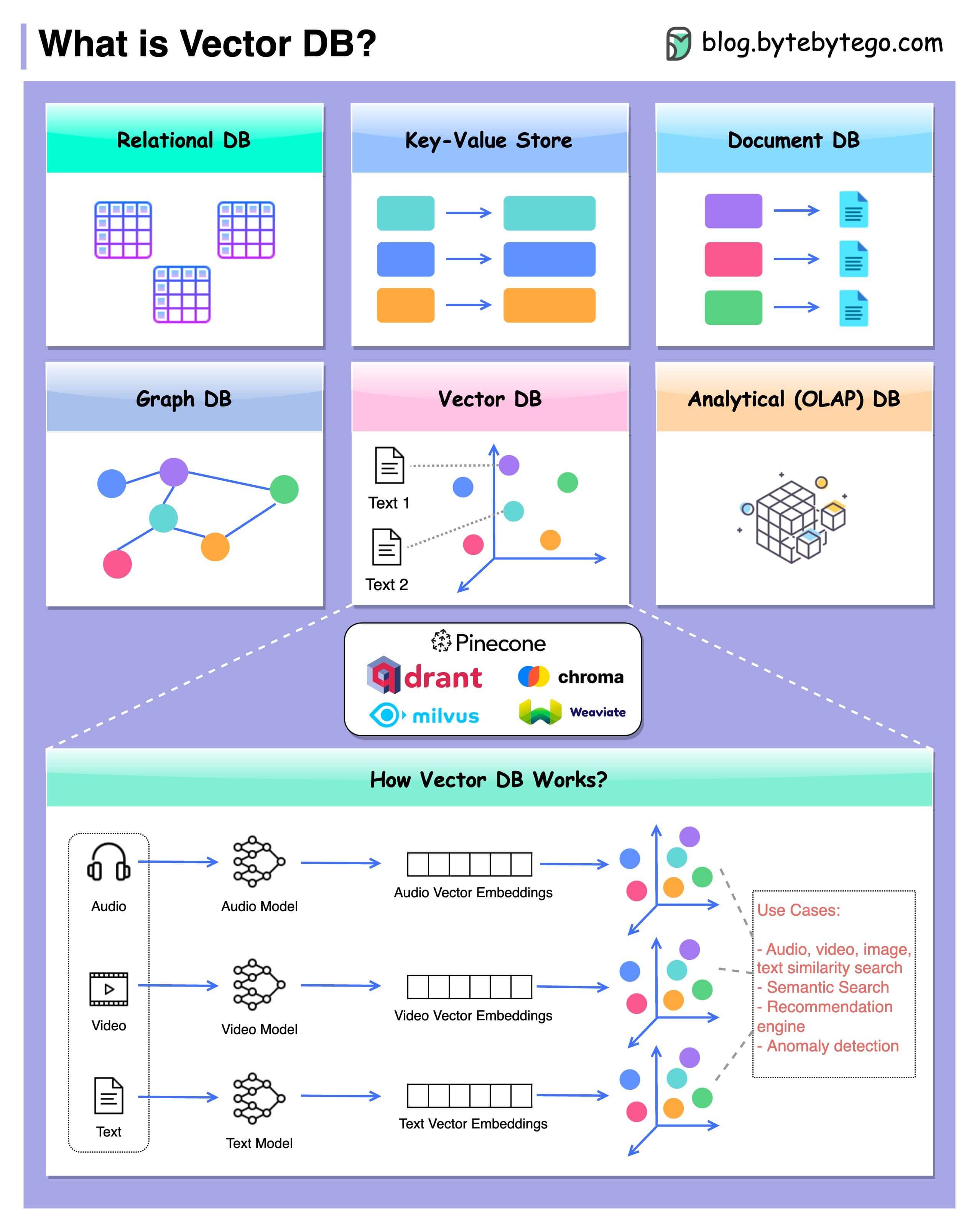
B. What Are Vector Databases?
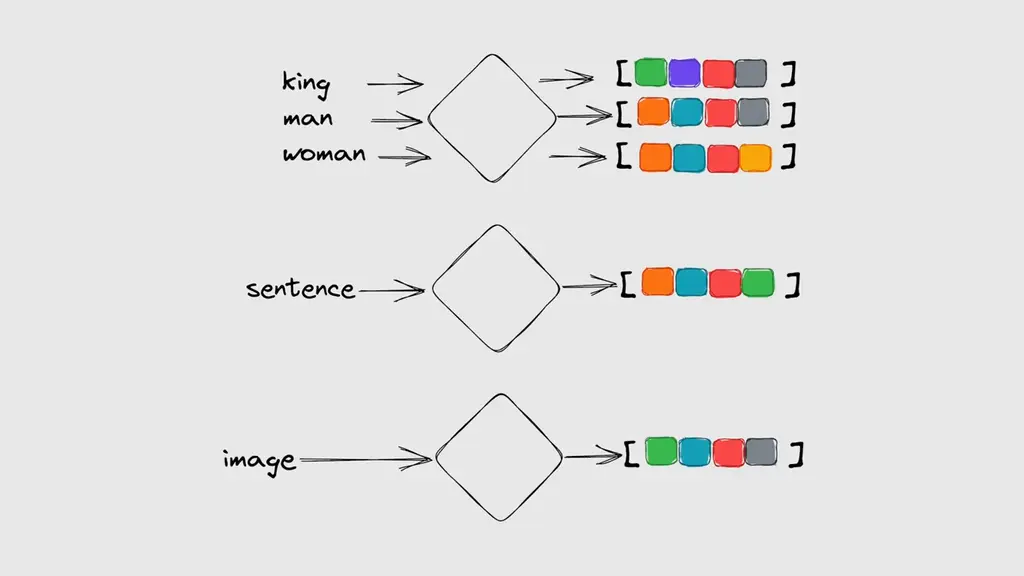
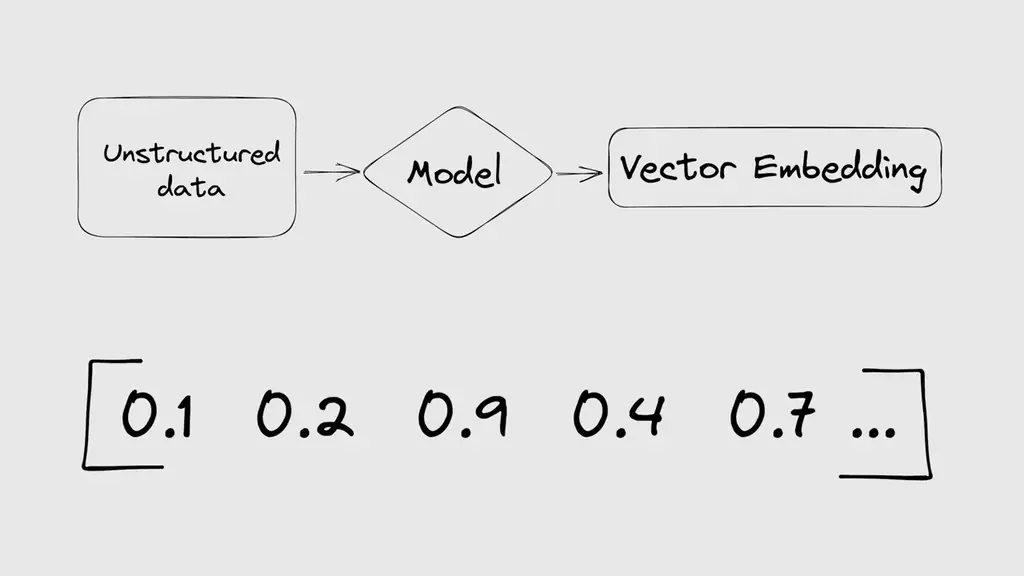
Image Credit: AssemblyAI
A vector database is a database that stores and manipulates data as vectors. A vector is an array of numbers that represents some features or attributes of the data. For example, an image can be represented as a vector of pixel values, a text document can be represented as a vector of word frequencies or embeddings, and a user profile can be represented as a vector of preferences or behaviors.
🔥 Vector databases are trending! But what exactly is a Vector DB?
— Anurag Vishwakarma | अनुराग विश्वकर्मा (@anurag_30) June 9, 2023
⚡️ A Vector DB indexes and stores vector embeddings for lightning-fast retrieval and similarity search. It offers CRUD operations, metadata filtering, and horizontal scaling capabilities.
Vector databases differ from traditional relational databases in several ways:
- First, vector databases do not rely on predefined schemas or tables to organize the data. Instead, they store the data as collections of vectors, which can have different dimensions and types.
- Second, vector databases do not use SQL or other query languages to access the data. Instead, they use vector operations, such as dot product, cosine similarity, or Euclidean distance, to measure the similarity or dissimilarity between vectors.
- Third, vector databases do not perform exact match or join operations on the data. Instead, they perform approximate nearest neighbour (ANN) search or retrieval, which is finding the most similar or relevant vectors from a large collection.
Anurag Vishwakarma
C. Key Components of Vector Databases
There are three key components of vector databases: Vector representation and storage, indexing and querying mechanisms, and integration with machine learning frameworks.
Vector Representation and Storage:
- This component converts and stores the raw data as vectors in a suitable format.
- Different methods for vector representation exist depending on the data type and complexity. For example:
Images can be represented using pixel values or feature extraction techniques.
Text documents can be represented using bag-of-words models or word embeddings.
User profiles can be represented using collaborative filtering or matrix factorization techniques.
- The choice of vector representation affects the quality and efficiency of the subsequent operations.
Indexing and Querying Mechanisms:
- This component builds and maintains indexes on the vectors to enable fast and accurate similarity search and retrieval.
- Different methods for indexing exist depending on the vector size and dimensionality. For example:
Tree-based methods partition the vector space into hierarchical regions.
Hashing-based methods map the vectors into binary codes.
Quantization-based methods compress the vectors into smaller representations.
- The choice of indexing method affects the trade-off between speed and accuracy of the queries.
Integration with Machine Learning Frameworks:
- This component connects the vector database with external machine learning frameworks to enable training and serving of vector-based models.
- Different methods for integration exist depending on the compatibility and functionality of the frameworks. For example:
Apache Arrow provides a common format for exchanging data between different frameworks.
Faiss provides a Python interface for accessing its C++ library.
TensorFlow provides a built-in module for performing ANN search on its tensors.
Anurag Vishwakarma
D. How Does Vector Databases Work?
A vector database is a type of database that stores and indexes vector embeddings for fast retrieval and similarity search. A vector database uses a combination of different algorithms that all participate in Approximate Nearest Neighbor (ANN) search. These algorithms optimize the search through hashing, quantization, or graph-based search.
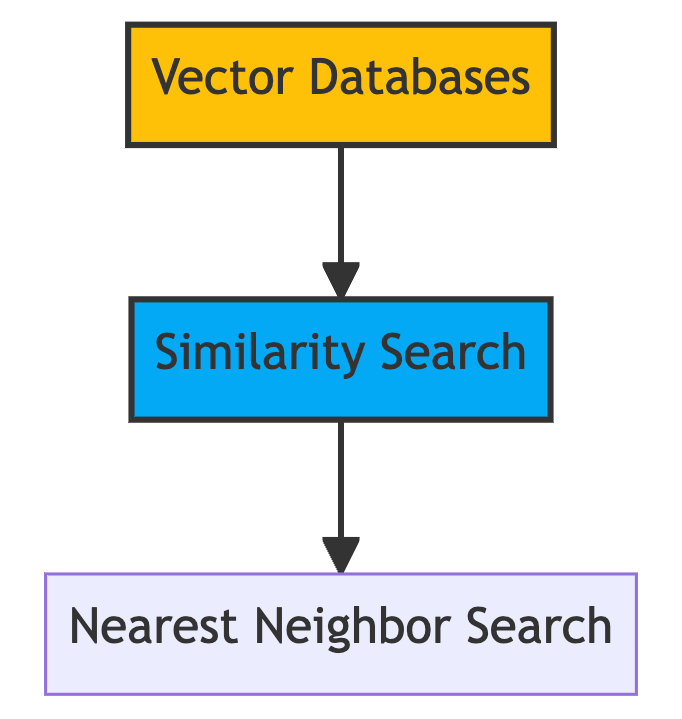
The basic idea of ANN search is to find the most similar vectors to a given query vector in the database. The similarity between two vectors can be measured by different metrics, such as cosine similarity or Euclidean distance. The higher the similarity score, the closer the vectors are in the vector space.
For example, if we have a query sentence "How do I train my dog?", we can use a machine learning model to calculate its embedding and then use a vector database to find the most similar sentences in our database. The vector database will return a ranked list of sentences with their similarity scores, such as:
"What are some tips for dog training?" (0.95)
"How can I teach my dog new tricks?" (0.92)
"How to train your puppy in 5 easy steps?" (0.89)
The same process can be applied to other types of data, such as images, audio, or video.
Advantages & Disadvantages of Vector Database
| Advantages of Vector Databases | Disadvantages of Vector Databases |
|---|---|
| Efficient storage and retrieval | Limited support for complex queries |
| Fast query processing | Limited ecosystem and tooling |
| High performance for analytics | Limited scalability |
| Native support for vector operations | Learning curve for developers |
| Simplified data modeling | Limited integration with existing systems |
| Suitable for machine learning | Limited support for transactional workloads |
E. Use Cases for Vector Databases
Vector databases have many use cases in various domains that require handling large amounts of complex and dynamic data and performing similarity search and retrieval on them. Some examples are:
1. Enhancing Search Engines and Recommendation Systems:
Vector databases can improve the quality and relevance of search results and recommendations by finding the most similar items based on their content or context rather than their keywords or metadata.
2. Improving Fraud Detection and Anomaly Detection:
Vector databases can detect fraudulent or anomalous transactions or activities by finding the most dissimilar items based on their patterns or behaviors rather than their labels or rules.
3. Optimizing Personalized Marketing and Customer Profiling:
Vector databases can segment customers based on their preferences or behaviors rather than their demographics or categories.
4. Content Generation:
Vector databases can help generate new content based on existing content or user input. For example, you can use a vector database to generate captions for images, summaries for articles, or lyrics for songs.
5. Knowledge Graphs:
Vector databases can help build and query knowledge graphs that store facts and relationships between entities. For example, you can use a vector database to answer questions about entities or concepts, such as "Who is the president of France?" or "What is the capital of Australia?".
6. Equipping LLMs with Long-Term Memory:
Vector databases can enhance large language models like GPT-4 by providing them with the ability to retain long-term memory. This feature enables improved context and semantic understanding in natural language processing tasks.
Anurag Vishwakarma
Vector Database Architectures
There are three main architectures for vector databases
1. On-disk Vector Databases
On-disk vector databases store the vectors on disk drives or other persistent storage devices. They use disk-based indexing methods to enable fast access to the vectors without loading them into memory. On-disk vector databases have several benefits:
- They can handle very large datasets that exceed the memory capacity.
- They can provide durability and fault-tolerance by replicating or backing up the data.
- They can reduce memory consumption and power consumption by avoiding unnecessary loading.
Drawbacks:
- They may suffer from disk latency and bandwidth limitations when accessing the data.
- They may incur additional overheads for disk management and maintenance.
- They may not support real-time updates or streaming data efficiently.
2. In-memory Vector Databases
In-memory vector databases store the vectors in memory devices such as RAM or GPU memory. They use memory-based indexing methods to enable fast access to the vectors without reading them from disk. In-memory vector databases have several advantages:
- They can provide very high performance and low latency when accessing the data.
- They can support real-time updates or streaming data efficiently.
- They can leverage parallelism and concurrency to speed up computations.
Limitations:
- They may not be able to handle very large datasets that exceed the memory capacity.
- They may not provide durability or fault-tolerance by default unless they use external storage devices.
- They may consume more memory resources and power resources than necessary.
3. Hybrid Vector Databases
Hybrid vector databases combine both on-disk and in-memory storage to achieve the best of both worlds. They store some vectors on disk drives for durability and scalability while storing some vectors in memory devices for performance and efficiency. Hybrid vector databases have several benefits:
- They can handle both large datasets and real-time updates or streaming data effectively.
- They can balance between speed and accuracy by using different indexing methods for different scenarios.
- They can optimize resource utilization by dynamically adjusting the storage allocation.
Challenges:
- They may require more complex design and implementation to integrate both storage types.
- They may introduce more inconsistency or complexity in query processing due to different storage types.
- They may need more tuning or configuration to achieve optimal performance.
Anurag Vishwakarma
💻 Vector Database Technologies
There are many technologies that support vector database functionality in various ways. Some of them are:
A. Apache Arrow
- Apache Arrow is an open-source project that provides a common format for exchanging data between different systems.
- Apache Arrow uses columnar storage to store data as arrays of values rather than rows of records. This enables faster processing and lower memory footprint.
- Apache Arrow supports various types of data such as scalar, nested, dictionary, extension, tensor, etc.
- Apache Arrow plays an important role in vector databases by enabling interoperability and compatibility between different frameworks that handle vector data.
- Apache Arrow provides libraries for popular programming languages such as Python, Java, C++, etc. that allow users to manipulate vector data easily.
B. FAISS
- Faiss is a popular library for efficient similarity search and clustering of dense vectors.
- Faiss is developed by Facebook AI Research (FAIR) and written in C++ with Python bindings.
- Faiss provides various methods for indexing high-dimensional vectors such as flat, inverted, product quantization, hierarchical navigable small world, etc.
- Faiss also supports GPU acceleration and distributed computing to scale up computations.
- Faiss can be used as a standalone library or integrated with other frameworks such as PyTorch.
C. TensorFlow
- TensorFlow is a widely used framework for developing and deploying machine learning models.
- TensorFlow supports various types of tensors such as dense, sparse, ragged, string, etc. that can represent vector data.
- TensorFlow also provides a built-in module called TensorFlow Similarity that allows users to perform ANN search on tensors using different metrics such as cosine, L2, inner product, etc.
- TensorFlow Similarity also supports model training.
Anurag Vishwakarma
⚠ Vector Database Challenges and Limitations
A. Data Privacy and Security
- Vector databases enable fast and efficient retrieval of data based on similarity and distance metrics.
- However, this also poses some challenges related to data privacy and security, especially when dealing with sensitive data such as biometric information, personal preferences, or medical records.
-
Some possible solutions are:
-
Encryption techniques to protect the data from unauthorized access, manipulation, or leakage, while preserving the ability to perform similarity search and analytics. However, encryption also introduces some trade-offs in terms of performance, complexity, and cost.
-
Differential privacy techniques to protect the data from revealing any information about an individual record in the database, while still providing useful statistical insights. Differential privacy can be achieved by adding carefully calibrated noise to the data or the query results. However, differential privacy also introduces some trade-offs in terms of accuracy, utility, and scalability.
-
Therefore, choosing the right solution and parameters is crucial for achieving a balance between security and efficiency.
B. Dimensionality and Complexity
- Vector databases are designed for high-dimensional data such as images, videos, audio, text, or graphs. However, high-dimensional data poses challenges related to dimensionality and complexity.
- The curse of dimensionality refers to the exponential growth of data space with the number of dimensions, making it harder to find meaningful patterns and similarities.
- To cope with the curse of dimensionality, vector databases can use dimensionality reduction techniques to reduce the number of dimensions.
- Dimensionality reduction can eliminate redundant or irrelevant features, compress data size, and improve performance and accuracy of similarity search and analytics. However, dimensionality reduction introduces trade-offs in terms of information loss, distortion, and interpretability.
- Choosing the right dimensionality reduction method and parameters is crucial for achieving a balance between simplicity and complexity. Another possible solution is to use indexing techniques to organize and optimize data in vector databases.
- Indexing can speed up similarity search and analytics by creating efficient data structures that facilitate fast access and retrieval of relevant data points. However, indexing introduces trade-offs in terms of storage space, update cost, and query flexibility.
- Choosing the right indexing method and parameters is crucial for achieving a balance between performance and scalability.
C. Maintenance and Updates
- Vector databases are dynamic and evolving systems that need to accommodate changes and updates to data over time. Maintenance and updates pose challenges related to consistency and efficiency.
- To ensure consistency and currency of data, vector databases can use synchronization techniques to propagate changes or updates across the network.
- Synchronization helps ensure all nodes or replicas have the same view of the data at any given time. However, synchronization introduces trade-offs in terms of communication overhead, latency, and availability.
- Choosing the right synchronization protocol and parameters is crucial for achieving a balance between consistency and availability.
- To handle updates and modifications to data without compromising performance or accuracy, vector databases can use incremental techniques.
- Incremental techniques update only the affected parts of the database, avoiding reprocessing or rebuilding the entire database whenever new data is added or existing data is changed. However, incremental techniques introduce trade-offs in terms of complexity, error propagation, and quality degradation.
- Choosing the right incremental method and parameters is crucial for achieving a balance between efficiency and accuracy.
Anurag Vishwakarma
🔎 What Are Some Options for Using Vector Databases?
You can use vector databases for your projects in different ways. Some ways are:
- Open-source libraries: These are tools that help you search for similar vectors. You need to write some code and set up some things to use them. Some examples are FAISS (Facebook AI Similarity Search), Annoy (Spotify), HNSW (Yandex), ScaNN (Google), and NMSLIB (Non-Metric Space Library).
- Open-source platforms: These are systems that help you make and manage vector databases. They have more features than libraries, such as storing data in many places, making it faster and safer, and checking how it works. Some examples are Milvus (Zilliz), Vespa (Verizon Media), Weaviate (SeMI Technologies), and Qdrant.
- Cloud services: These are services that help you use vector databases without writing code or setting up anything. They connect with your data and models easily through APIs or SDKs.
Some Popular Vector Database Options
Several vector databases are available, each offering unique features and capabilities. Some notable options include:

| Vector Database | Description |
|---|---|
| 1. Pinecone | A cloud service that provides scalable and accurate vector similarity search. |
| 2. Weaviate | An open-source platform that enables semantic search and knowledge graph creation. |
| 3. Chroma | An open-source library that provides a fast and flexible vector database. |
| 4. Redis | A popular in-memory database that supports various data types, including vectors. |
| 5. Qdrant | An open-source platform that provides a distributed vector similarity search engine. |
| 6. Milvus | An open-source platform that provides a cloud-native vector database for AI applications. |
| 7. Vespa | An open-source platform that provides a big data serving engine with vector search capabilities. |
If you desire an in-depth comparison, please let us know in the comments section below, and we will consider creating a separate video to address that topic.
😀 Conclusion
Vector databases are a powerful tool in the world of AI. They can efficiently store, retrieve, and search for complex and unstructured data. These databases are especially useful for handling large language models and enabling smarter searches. They provide long-term memory and a deep understanding of the meaning behind data for AI models. With vector databases, businesses can improve their data processing, find similar items quickly, and make better recommendations.
firstfinger firstfinger
firstfinger Anurag Vishwakarma
Anurag Vishwakarma
FAQs
What is a vector database?
A vector database stores mathematical representations of objects in multi-dimensional space, enabling efficient retrieval and operations like similarity searches and clustering.
How does a vector database work?
Vector databases use specialized indexing structures and algorithms to organize vectors, facilitating fast search and retrieval based on metrics, nearest neighbors, and dimensionality reduction methods.
What are common use cases for vector databases?
Vector databases are used in recommendation systems, image analysis, natural language processing, anomaly detection, bioinformatics, and financial analysis for tasks such as personalized recommendations, content-based search, semantic analysis, and fraud detection.
What are the advantages of vector databases?
Vector databases offer efficient similarity search, scalability for large datasets, flexibility for different vector types and dimensions, and built-in operations like clustering and classification, simplifying machine learning and data analysis workflows.
What are popular vector databases?
Popular vector databases include Apache Cassandra, FAISS, Elasticsearch, Milvus, and Neo4j, each offering scalability, optimized search, distributed capabilities, and support for vector operations and similarity search.