How to Test the Accuracy, Risks, and Reliability of LLMs with Deepchecks?
Deepchecks make it easy for users to validate their data and find issues. It has many pre-built checks, each designed to find different issues with data integrity, distributions, model performance, and more.

As large language models (LLMs) grow more capable with billions of parameters, validating their responsible behaviour throughout training, testing and deployment lifecycles becomes too complex and essential. The accuracy of a language model refers to how well it's able to generate relevant, factually correct, and coherent text.
While Pre-deployment testing tends to focus narrowly on metrics like perplexity that reward fluent text generation. However, fluency alone cannot guarantee LLMs behave responsibly when deployed.
- Accuracy - Producing relevant, factually correct responses grounded in an input context.
- Safety - Avoiding harmful biases, toxicity, privacy violations, or other unsafe behaviours.
How do Training Data Problems Affect LLMs?
The training data used for LLMs directly impacts their performance, risks, and reliability. LLMs like GPT-3 are trained on massive text datasets scraped from the internet, absorbing all the biases and flaws present in the data.
This type of training data can generate harmful stereotypes, generate toxic or nonsensical outputs, and cause the LLM to fail when deployed.
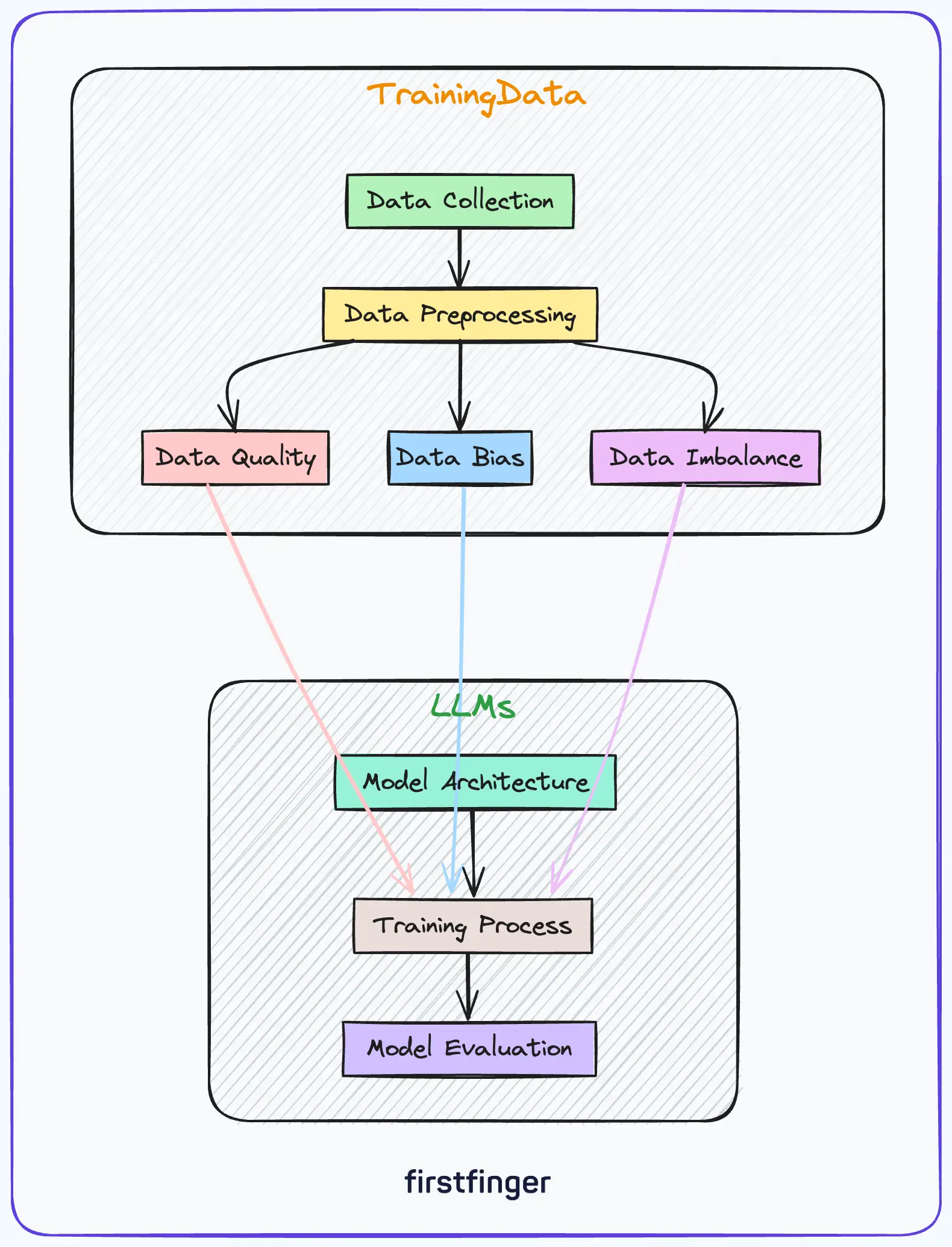
Several issues can arise with low-quality training data:
- Poor data integrity: Errors in formatting, incorrect labels, duplicated samples, etc. directly lower model accuracy.
- Data imbalances: Skewed distributions in features or labels diminish model performance on underrepresented classes.
- Data drift: If training data is not representative of real-world data, the LLM fails to generalize.
- Data biases: Stereotypes, toxic language, and other issues from non-diverse data become embedded in the LLM.
- Annotation errors: Incorrect human-generated labels used for supervised learning reduce accuracy.
Thorough testing and validation of training data characteristics like distribution, integrity, and quality are essential before training large LLMs. This helps prevent data problems from undermining model capabilities.
 Anurag Vishwakarma
Anurag Vishwakarma
The Challenges of Testing LLMs
LLMs present unique testing challenges compared to traditional software:
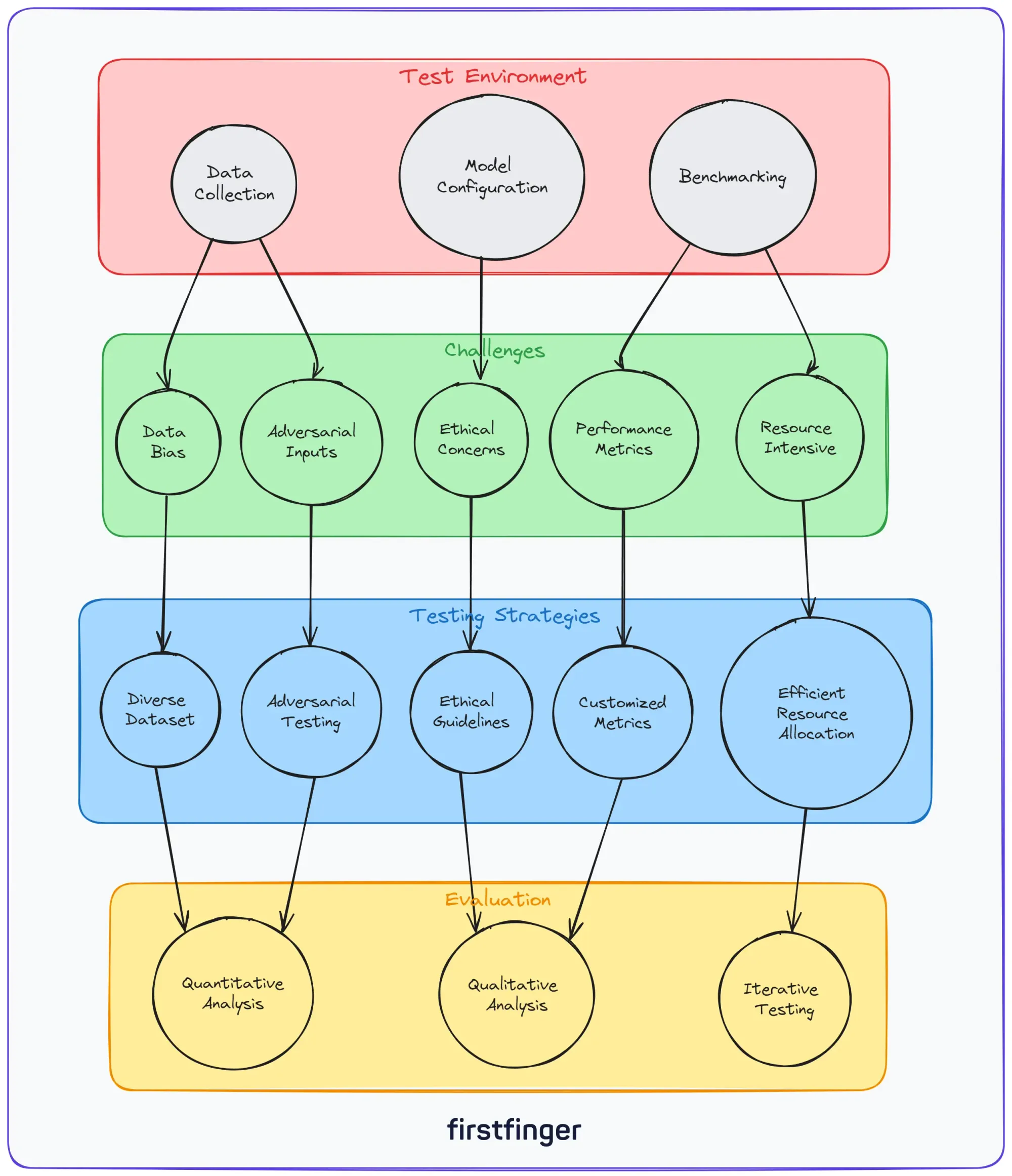
- Black box nature: As deep neural networks, LLMs are complex black boxes with billions of parameters. Their inner workings are difficult to interpret.
- Probabilistic outputs: LLMs generate probabilistic text predictions rather than deterministic outputs. There may be multiple valid responses for a given input.
- Silent failures: Issues like bias and toxicity often manifest subtly in text. Without rigorous testing, these problems can go undetected.
- Difficulty of gold standards: Given the variability of language, defining objective "gold standards" for evaluating generations is not straightforward.
- Scalability: As dataset size and model complexity increase, manually annotating test data does not scale well.
These challenges underscore the need for an automated, comprehensive testing approach spanning accuracy, ethics, and other issues.
Challenges in Assessing LLMs Accuracy
LLMs showcase impressive fluency. But open-ended dialogue poses new accuracy challenges:
- Subjective Quality - Relevance involves human subtlety that is difficult to automate.
- No Single Correct Response - Dialogue naturally has many appropriate responses.
- Hallucination Risk - Without proper grounding, there's a risk of uncontrolled imagination.
- Reasoning Limitations - LLMs may struggle with weak logical and common-sense capabilities.
These factors mean accuracy requires slight human assessment beyond common benchmarks. LLM evaluation should facilitate efficient oversight.
Risks of Deployed LLMs
In addition to accuracy, deployed LLMs risk perpetuating harm via:
- Implicit Bias - Absorbing societal biases from training data.
- Explicit Toxicity - Exposure to harmful content that leaks into behaviour.
- PII Leaks - Revealing private data referenced during training.
Safety assessment requires continuously probing outputs for multiple potential pitfalls. Comprehensive protection demands an integrated solution.
Anurag Vishwakarma
Evaluating Accuracy Properties
#1. Relevance
Does the model generate text relevant to the input and task? If it goes off-topic or gives unrelated information, it's not relevant.
#2. Fluency
How well-written and grammatically correct is the generated text? Lack of fluency suggests model uncertainty.
#3. Factual Consistency
Does the model contradict itself or state false facts? This can make users lose trust in the model.
#4. Logical Reasoning
Can the model successfully follow logical reasoning chains? Faulty logic diminishes applicability for complex tasks.
Evaluating these facts often requires human judgment. However, for certain tasks like summarization, tools like ROUGE can measure how much the model's output matches reference summaries.
#5. Adaptive, Dual Evaluation
Given probabilistic outputs, multiple responses may be valid for a particular input. Singular "gold standards" are often insufficient. Testing systems should consider multiple possible answers.
Risk Management Properties
#1. Bias
Testing bias involves checking for skewed model performance on inputs related to sensitive attributes like gender, race, etc. Debiasing strategies like adversarial training can help mitigate issues.
#2. Toxicity
LLMs have exhibited toxic outputs including hate speech, abuse, and threats. Rigorously screening for these concerns is critical before deployment.
#3. Privacy Leakage
LLMs may unintentionally expose or generate private information about users in outputs. Checks for personal info leakage should occur.
Automated testing is crucial to detect hard-to-spot risks in various scenarios. Without comprehensive evaluations, competent models can exhibit harmful behaviour when deployed.
Anurag Vishwakarma
How Can Deepchecks Help Make the LLMs Production-Ready?
Deepchecks make it easy for users to validate their data and find issues.
Documentation →The Deepchecks platform provides data quality monitoring and model evaluation capabilities specially built for common AI validation needs and LLM testing. Deepchecks LLM Evaluation offers a version purpose-built for continuously testing LLMs pre and post-deployment.
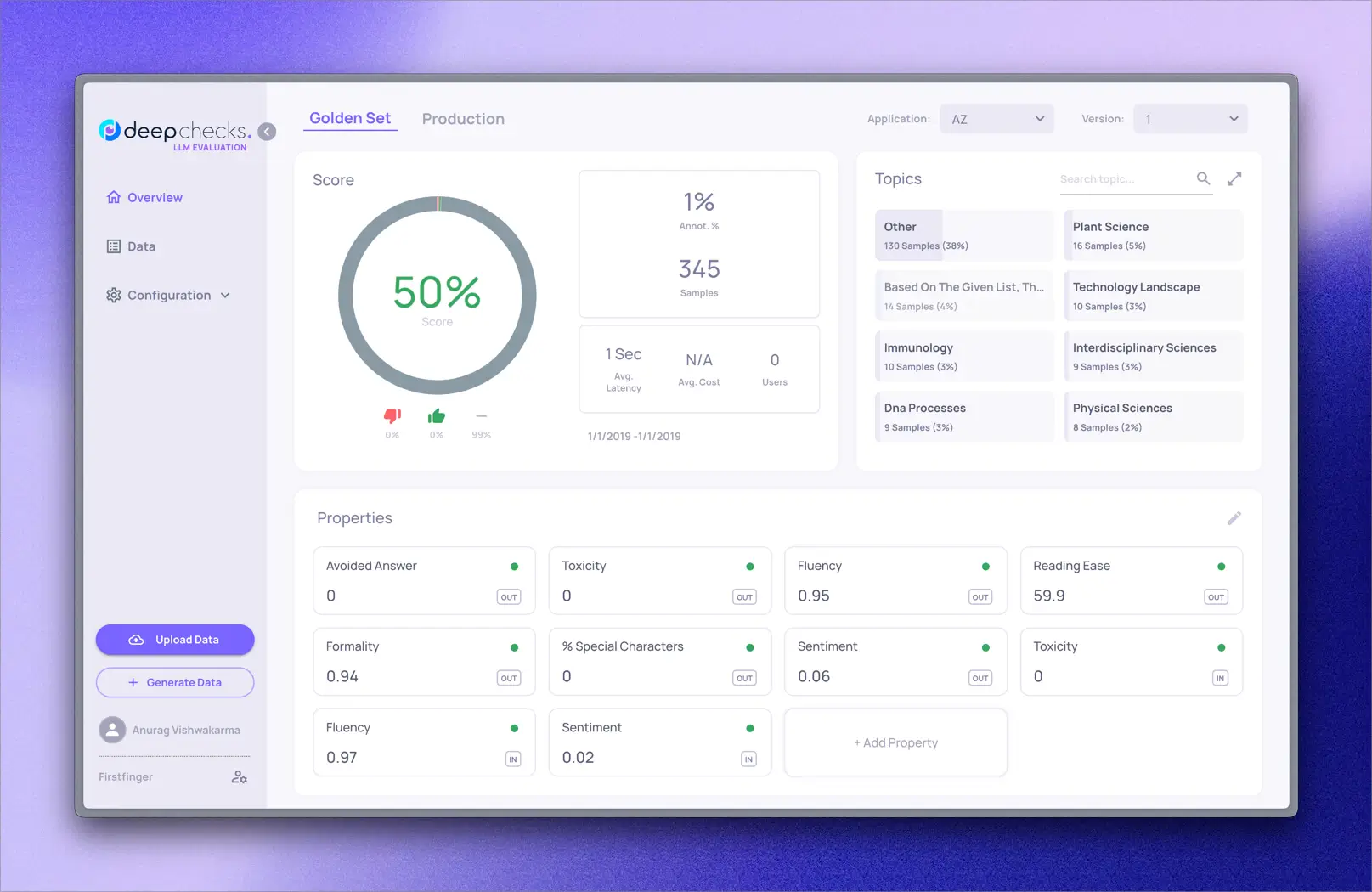
LLM Evaluation combines automated analysis with tools optimizing human oversight to efficiently validate both accuracy and safety throughout the LLM lifecycle.
What Can Deepchecks Do with Your Training Data?
Deepchecks leverage your training data in several important ways to establish baselines and evaluate model drift. It checks the integrity of the training data itself for issues like missing values or duplicates that could affect model performance.
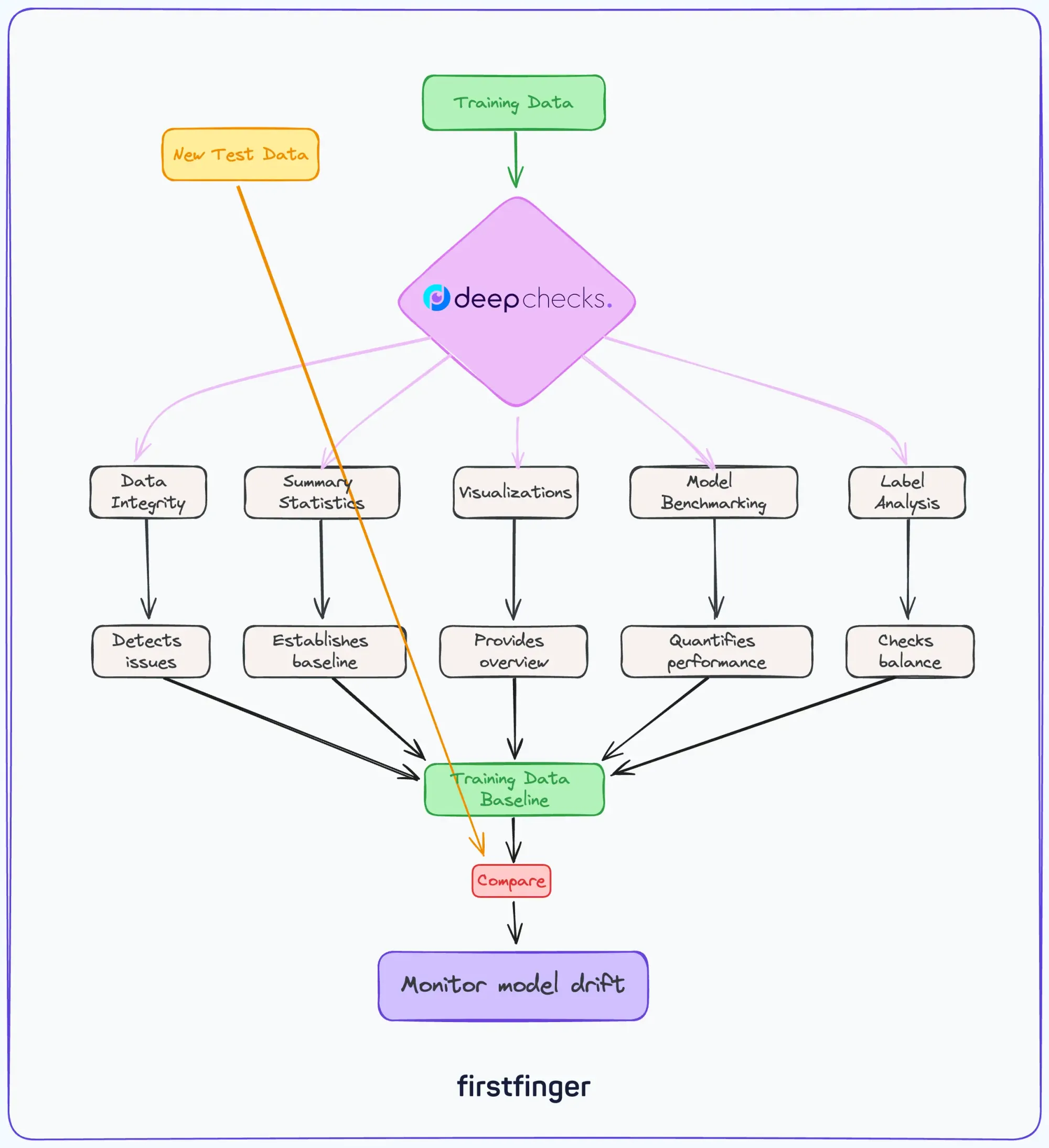
Deepchecks also analyzes properties of the training data including summary statistics of features, visualizations of feature distributions, and analysis of label balance and ambiguity. Furthermore, it trains simple benchmark models on the training data to quantify model performance and generalizability.
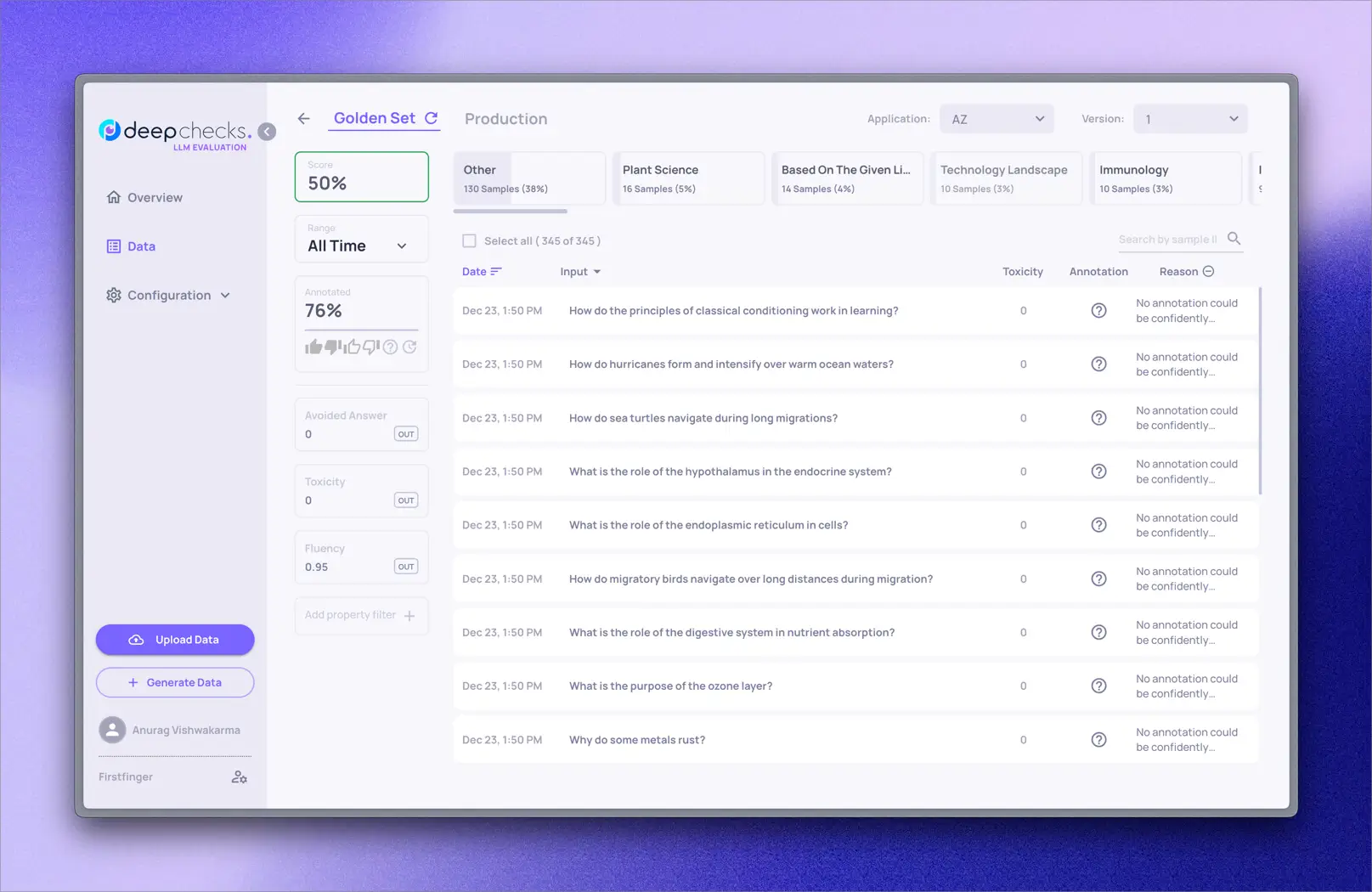
The key comparisons Deepchecks makes are between metrics and properties derived from the training data versus those same metrics on new test data. This allows Deepchecks to detect data drift, changes in model performance, overfitting, and other issues that can occur after models are deployed.
Deepchecks Features:
- Pre-built checks for data integrity, model evaluation, bias, toxicity, and more.
- Automated anomaly detection surfaced through interactive reports.
- Integration with popular ML frameworks like TensorFlow and PyTorch.
- Comparison across pipeline stages to catch emerging issues.
- Monitoring production models with user-defined alerting.
- Collaboration tools for team-based quality assurance.
Flexible Accuracy Testing
- Human-in-the-Loop Review - Manual rating interfaces assess subjective quality factors.
- Accuracy Estimation - Customizable automated quality scoring based on metrics tailored to dialogue.
- Context Grounding Checks - Detect hallucinated responses not based on provided context.
- Consistency Checks - Identify contradictory responses on repeated inputs.
SafetyGuard Testing
- Bias Detectors - Tests proactively probing for implicit biases.
- Toxicity Checks - Screens for offensive, harmful language.
- Leakage Identification - Flags potential private data exposure.
- Adversarial Probing - Stress tests model boundaries.
Data Management & Analysis
- Version Comparison - Contrast QA sets between iterations for regressions.
- Traffic Analysis - Track query volumes and trends.
- Segmentation - Filter and drill into underperforming segments.
- Explainability - Interactive reports trace failures to root causes.
Anurag Vishwakarma
How to Evaluate Model Data with Deepchecks?
High-quality data is very important for building accurate machine-learning models. However, model data can degrade over time, leading to silent model failures if not caught early.
First, What is Model Data?
Model data refers to the features (X) and labels (y) used to train and evaluate machine learning models. This includes:
- Training features and labels - Used to train the model
- Validation features and labels - Used to evaluate and tune the model during development
- Test features and labels - Used to provide an unbiased evaluation of the final model
Let's Get Started with Deepchecks
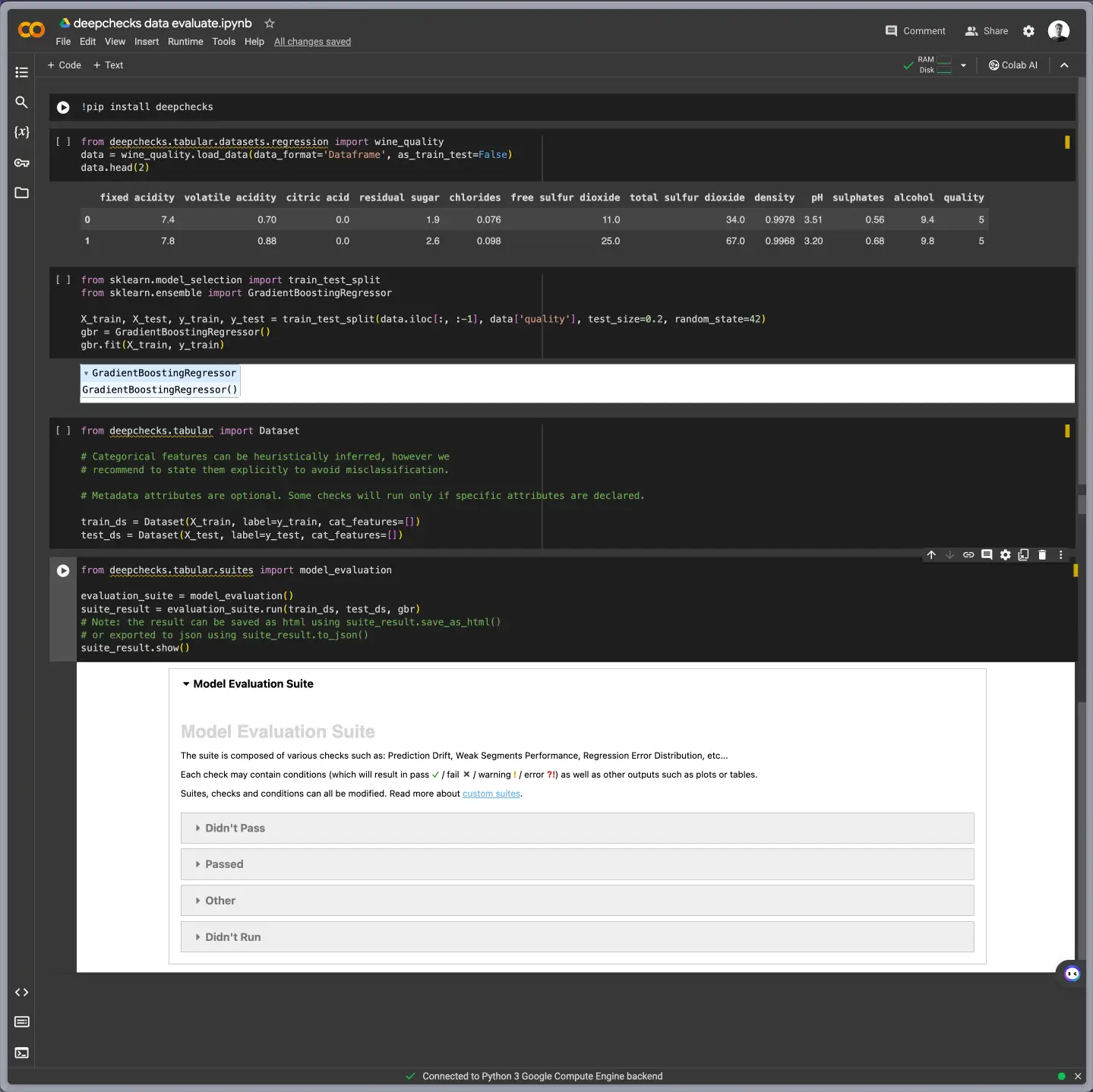
To use Deepchecks, you first need to install the library:
pip install deepchecks
Then import it:
from deepchecks.tabular import Dataset, Suites
The components we'll use are Dataset to store our data, and Suites contain drift checks.
Creating the Dataset
We first need to load our training and test data into the Deepchecks Dataset format:
from deepchecks.tabular import Dataset
train_ds = Dataset(X_train, y_train)
test_ds = Dataset(X_test, y_test)
This structures our data for Deepchecks to analyze.
Analyzing the Data
Next, we can create and run suites to analyze different aspects:
# Data integrity
integrity_suite = data_integrity()
integrity_suite.run(train_ds)
# Visualizations
visualization_suite = simple_ suites.feature_suites.train_test_feature_distribution()
visualization_suite.run(train_ds, eval_ds)
# Model performance
perf_suite = simple_suites.model_evaluation.train_test_model_performance()
perf_suite.run(train_ds, eval_ds)
Deepchecks performs several analyses on the training data when evaluating data:
- Training Data Integrity - Checks for issues like null values, duplicates, and data errors to ensure the training data is high quality.
- Training Data Summary - Computes summary statistics like mean, standard deviation, class balance, etc. This establishes a baseline for comparison.
- Training Data Visualization - Creates plots summarizing the distribution of the training data features. This provides a visual summary of the data.
- Model Performance on Training Data - Trains a simple model on the training data and evaluates performance metrics like accuracy, AUC, etc. This checks how well the model can fit the training data.
- Training Label Analysis - Analyze the distribution of labels and check for issues like imbalanced classes or ambiguous labels.
- Training Data Drift - Compares the training data to reference datasets to detect drift or changes in the data over time.
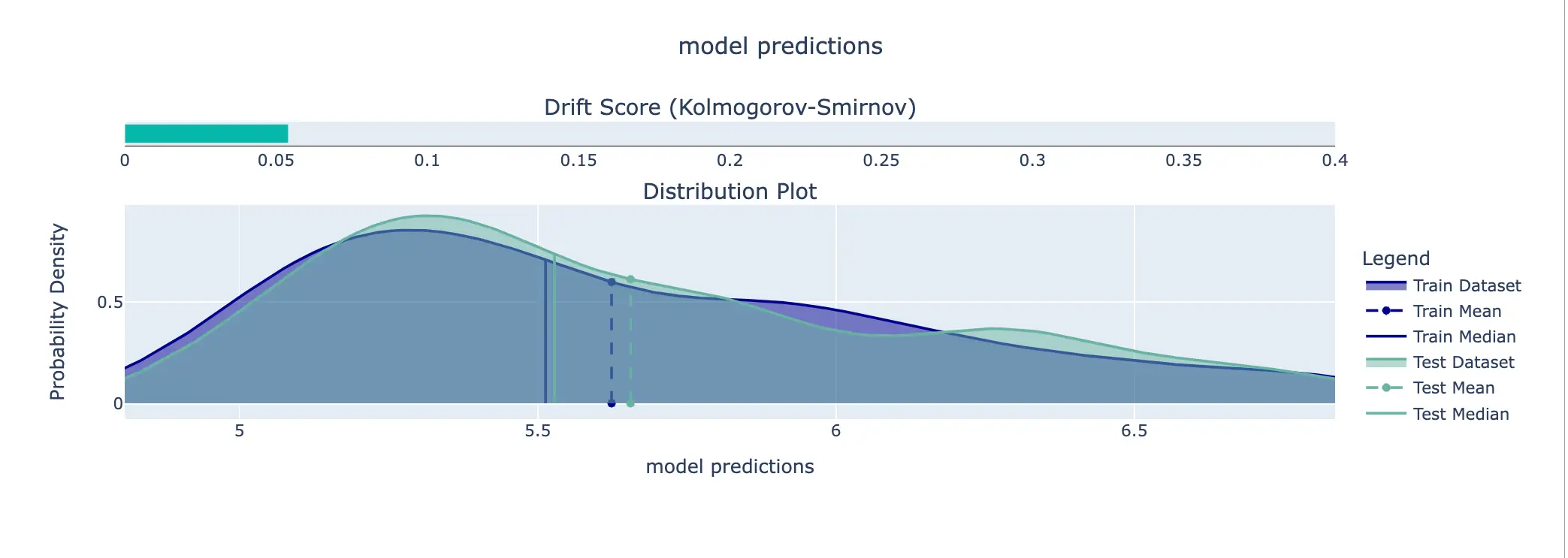
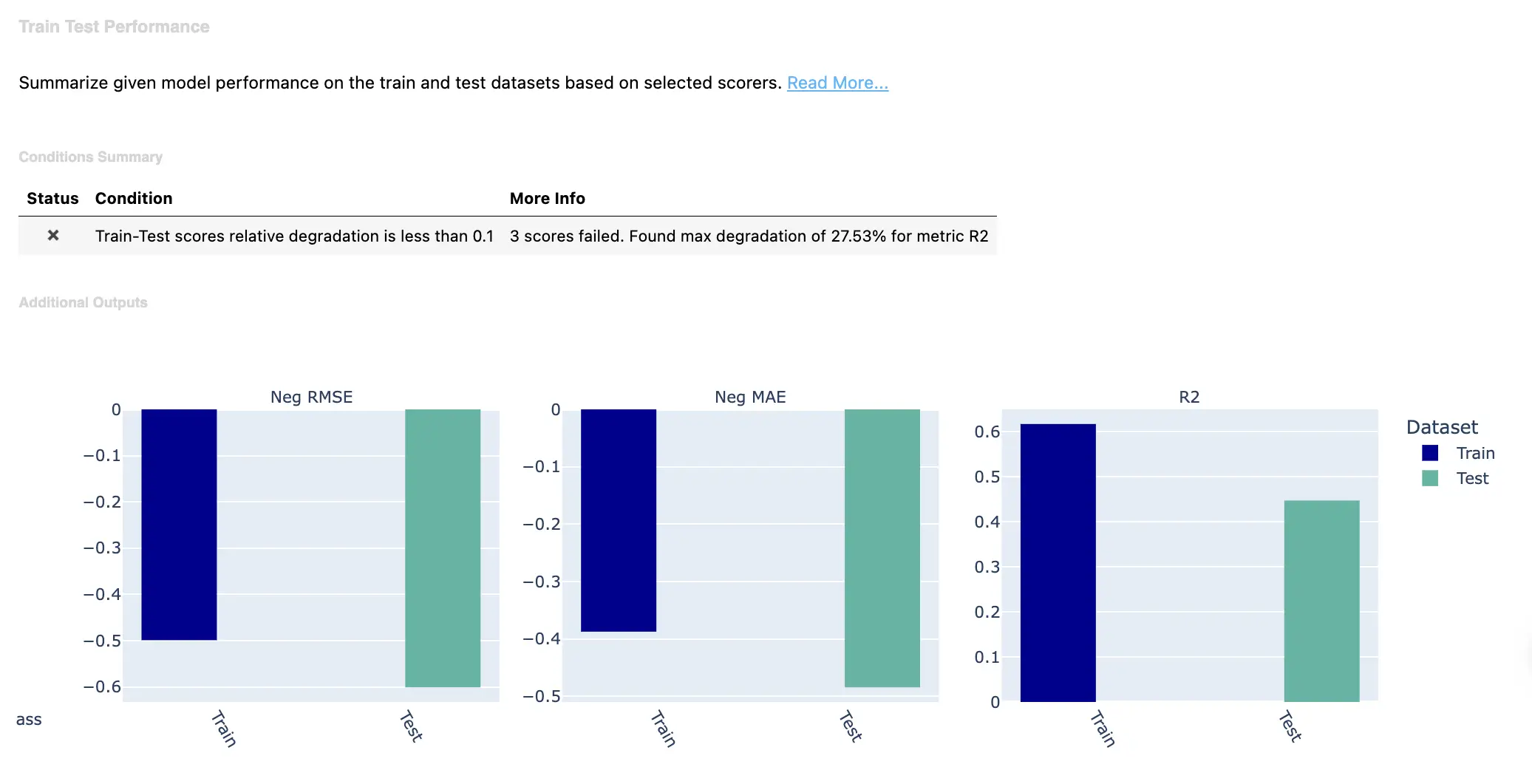
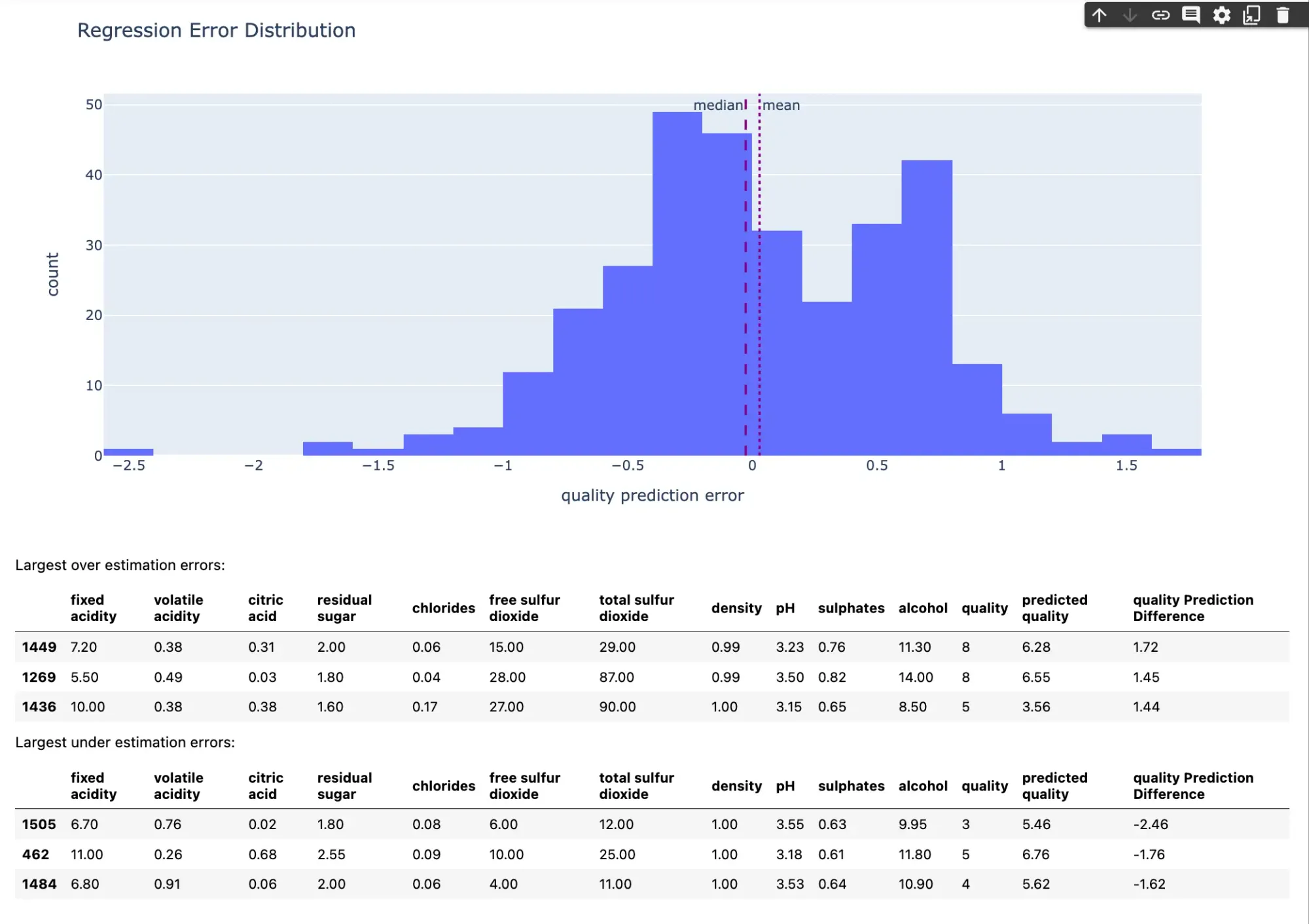
This performs checks on data integrity, visualizations, and model performance.
Monitoring Over Time
We can run these suites each time new data is acquired to monitor for issues over time. For example, degrading model performance could indicate label problems. Diverging distributions between train and eval data may signify data drift.
Data evaluation with deepchecks library in Python
Deepchecks uses the training data to understand the data properties, model performance bounds, and label characteristics. It then monitors how these change on new test data once the model is deployed.
Deepchecks make it easy to continuously validate model data quality. This helps identify and resolve issues early to build more robust models.
LLMs should be evaluated during:
- Experimentation - Comparing candidate designs.
- Staging - Vetting versions before launch.
- Production - Monitoring live systems.
However optimal testing strategies differ across stages.
Deepchecks LLM Evaluation provides integrated solutions for LLM validation challenges. Configurable accuracy metrics, safety probes, human review loops, staged testing, and transparent reporting enable continuous vetting of LLMs responsibly.
Better Data is Better Than Better Models
Anurag Vishwakarma Anurag Vishwakarma
Anurag Vishwakarma Anurag Vishwakarma
Anurag Vishwakarma