
Should You Use Open Source Large Language Models?
The benefits, risks, and considerations associated with using open-source LLMs, as well as the comparison with proprietary models.
Large language models (LLMs) powered by artificial intelligence are gaining immense popularity, with over 325,000 models available on Hugging Face. As more models emerge, a key question is whether to use proprietary or open-source LLMs.
What are LLMs and How Do They Differ?
- LLMs leverage deep learning and massive datasets to generate human-like text
- Proprietary LLMs are owned and controlled by a company
- Open-source LLMs are freely accessible for anyone to use and modify
- Proprietary models currently tend to be much larger in terms of parameters
- However, size isn't everything - smaller open-source models are rapidly catching up
- Community contributions empower the evolution of open-source LLMs
 Anurag Vishwakarma
Anurag Vishwakarma
Benefits of Open Source LLMs
- Transparency - Better visibility into model architecture, training data, output generation
- Customization through fine-tuning custom datasets for specific use cases
- Community contributions across diverse perspectives enable experimentation
Use Cases
Open-source LLMs are being deployed across industries:
- Healthcare
- Diagnostic assistance
- Treatment optimization
- Finance
- Applications like FinGPT for financial analysis
- Science
- Models like NASA's trained on geospatial data
Leading Models on Hugging Face
The Hugging Face model leaderboard's latest benchmarks.
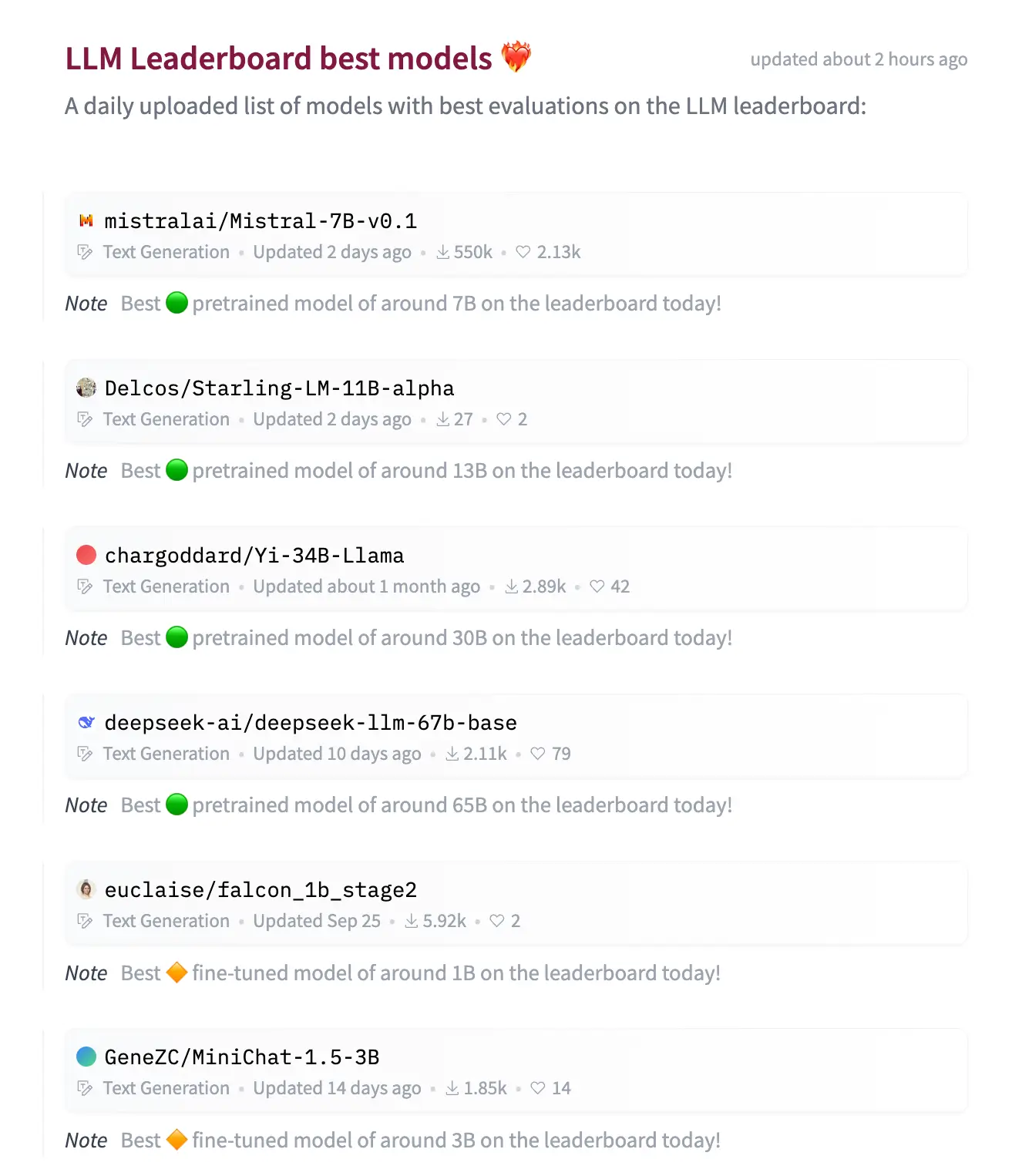
- Currently, variations on Meta's LLM2 lead - spanning with 7-70 billion parameters and commercially usable
- Other top models include:
- Mistral-7B is a transformer model and beats Llama 2 13B in all the tests.
- Deepseek LLM has been trained on a vast dataset of 2 trillion tokens in English and Chinese.
Anurag Vishwakarma
Downside of Open-source LLMs
Despite advances, LLMs have concerning have 3 major limitations:
- Inaccuracy - Hallucinations from inaccurate/incomplete training data
- Security - Potential exposure of private data in outputs
- Bias - Embedding biases that skew outputs
Mitigating these risks in early-stage LLMs remains vital.
The Bottom Line
Open-source big language models make AI more available to everyone. This widens who can use them. But risks are still there. Even so, putting information out in the open and letting users adjust models to their needs gives power to people across fields.