
What is Apache Kafka & Why it is fast?
How the Apache Kafka has become the go-to solution for real-time data streaming, handling massive volumes of data.

In today's fast-paced digital world, businesses require solutions that can handle massive data volumes and process them in real-time. This is where Apache Kafka comes in. Apache Kafka has quickly become the preferred option for real-time data streaming across various industries. But what is Apache Kafka, and how does it achieve such impressive speed and performance?
More than 80% of all Fortune 100 companies trust, and use Kafka.
♨️ What is Apache Kafka?
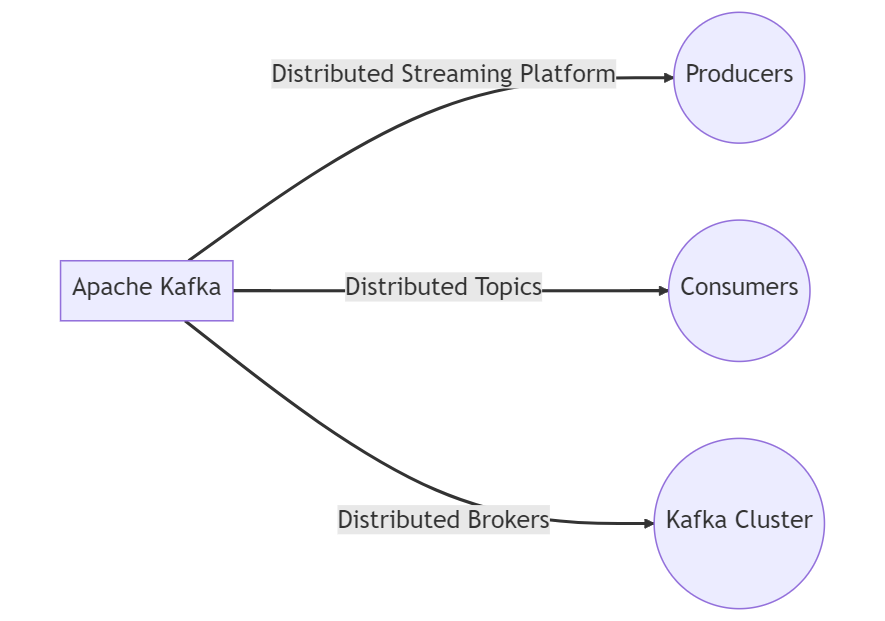
Apache Kafka is an open-source distributed streaming platform that was created by LinkedIn in 2011. It is designed to handle massive volumes of data in real-time, making it an ideal solution for streaming applications. Kafka is a distributed system that runs on a cluster of servers, and it is designed to be highly scalable, fault-tolerant, and highly available.
💬 Fundamentals of Apache Kafka
Kafka is built around the concept of topics, which are a way of organizing data streams. Producers write data to topics, and consumers read data from topics. Kafka uses a publish-subscribe model, where producers publish messages to a topic, and consumers subscribe to topics to receive messages. Each message in Kafka consists of a key, a value, and a timestamp.
🔧 Architecture of Apache Kafka
Kafka's architecture is composed of four main components: producers, consumers, brokers, and ZooKeeper. Producers write data to Kafka topics, consumers read data from Kafka topics, brokers manage the storage and replication of data, and ZooKeeper manages the coordination of the cluster. Kafka's distributed nature allows it to scale horizontally across many servers, making it highly scalable and fault-tolerant.
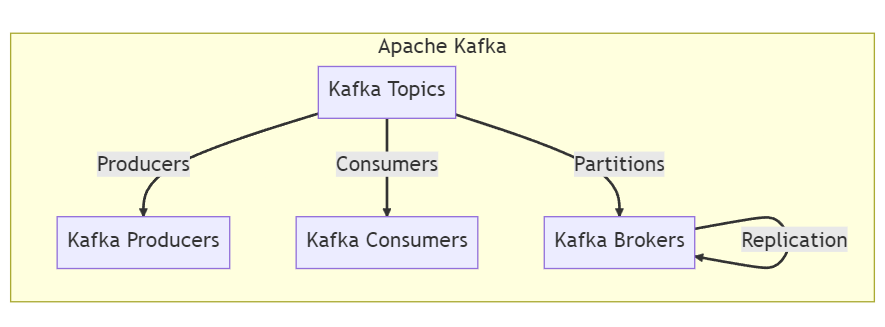
👇 The key components of Kafka's architecture include:
- Kafka Topics: Topics are the channels through which data streams are organized and categorized. Producers publish messages to specific topics, and consumers subscribe to those topics to consume the data.
- Kafka Producers: Producers are responsible for publishing data to Kafka topics. They can be any application or system that generates data and wishes to make it available for consumption.
- Kafka Consumers: Consumers are the applications or systems that subscribe to Kafka topics and consume the data. They can read data in real-time or at their desired pace.
- Kafka Brokers: Kafka brokers are the nodes that form the Kafka cluster. They handle the storage, replication, and distribution of data across the cluster.
- Kafka Partitions: Topics can be divided into multiple partitions, allowing data to be distributed across different brokers. Partitions enable parallel processing and high scalability.
- Kafka Replication: Kafka employs replication to ensure data durability and fault tolerance. Each partition can have multiple replicas spread across different brokers, providing redundancy.
⚙️ How does Apache Kafka works ?
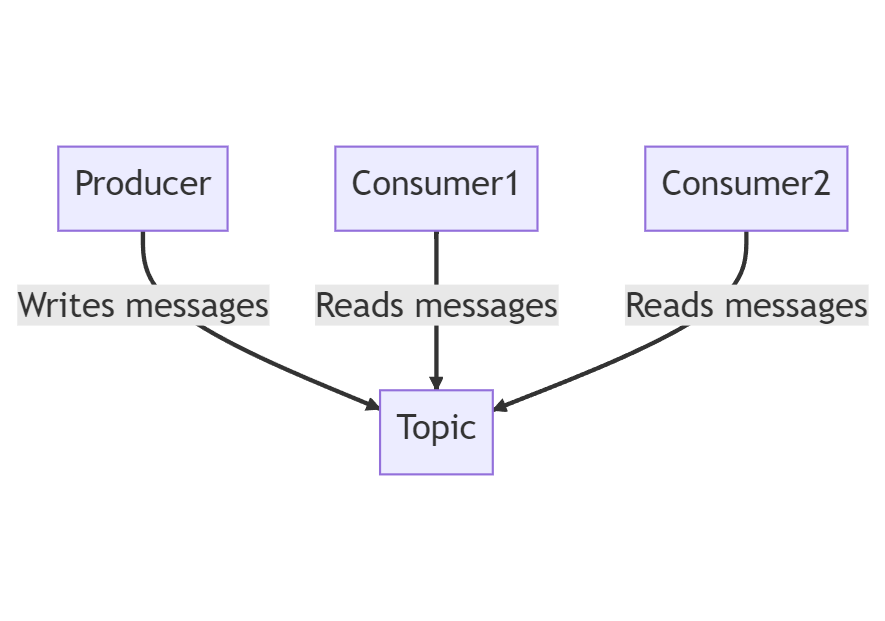
In other words, Apache Kafka is a distributed streaming platform that allows for the reliable and scalable handling of real-time data feeds. It is built on a publish-subscribe model, where producers publish data to specific topics, and consumers subscribe to those topics to consume the data.
At its core, Apache Kafka consists of three main components: producers, topics, and consumers.
- Producers: Producers are responsible for writing and publishing data to Kafka topics. They can be any application or system that generates data and wants to make it available for consumption. Producers send data to specific topics, which act as channels for organizing and categorizing the data.
- Topics: Topics in Apache Kafka represent the channels through which data streams are organized and categorized. They serve as the central hub for data storage and distribution. Producers publish messages to specific topics, and consumers subscribe to those topics to consume the data. Topics can be partitioned, allowing for parallel processing and high scalability.
- Consumers: Consumers are the applications or systems that subscribe to Kafka topics and consume the data. They read data in real-time or at their desired pace. Each consumer keeps track of its progress in reading the data, enabling fault tolerance and scalability. Multiple consumers can read from the same topic, forming consumer groups.
→ In addition to these components, Kafka utilizes a distributed architecture consisting of multiple Kafka brokers. These brokers form a cluster, where each broker is responsible for handling the storage, replication, and distribution of data across the cluster. Kafka brokers store the messages in durable storage and keep multiple copies of each partition to ensure fault tolerance and data reliability.
→ When data is produced by a producer, it is sent to a specific topic and partition within the Kafka cluster. The data is then replicated across multiple brokers for redundancy and durability. Consumers subscribe to the desired topics and partitions and receive the data in a continuous stream. Kafka tracks the offset or position of each message, allowing consumers to read the data in order and ensuring data consistency.
→ Apache Kafka is known for its exceptional speed and efficiency due to several factors. Firstly, it utilizes an efficient disk-based storage mechanism combined with an in-memory caching layer, enabling high throughput and low latency. Secondly, Kafka's distributed architecture allows for horizontal scalability by adding more brokers to the cluster, enabling seamless handling of large data volumes.
Apache Kafka's Speed and Performance
One of the main reasons why Kafka has become the go-to solution for real-time data streaming is its impressive speed and performance. Kafka can handle millions of messages per second, making it faster than many traditional messaging systems. Additionally, Kafka's distributed nature allows it to scale horizontally, making it highly scalable and fault-tolerant.
⚡️ Performance Optimization
Performance optimization in Apache Kafka is crucial for achieving optimal throughput and low latency in data streaming scenarios.
Here are some key strategies to optimize Kafka's performance:
- Proper Hardware Provisioning: Ensure that Kafka has sufficient resources, including CPU, memory, and disk storage, to handle the expected workload efficiently.
- Topic Partitioning: Divide data across multiple partitions to enable parallel processing and distribute the load among Kafka brokers.
- Batch Size and Compression: Adjust producer batch size and compression settings to optimize network utilization and reduce overhead.
- Configuration Tuning: Fine-tune Kafka configuration parameters such as replication factor, retention period, and buffer sizes to match the specific requirements of your use case.
- Consumer Group Management: Effectively manage consumer groups by balancing the workload across consumers and controlling the rate of data consumption.
- Monitoring and Metrics: Utilize monitoring tools and Kafka's built-in metrics to identify performance bottlenecks, monitor cluster health, and make informed decisions for optimization.
- Upgrade to Latest Versions: Stay up-to-date with the latest Kafka versions, as they often include performance improvements and bug fixes.
- Network Considerations: Ensure low network latency and sufficient bandwidth between producers, consumers, and Kafka brokers to avoid delays in data transmission.

👉 Advantages & Disadvantages of Apache Kafka
Apache Kafka offers numerous advantages and disadvantages that make it a popular choice for handling real-time data streams: Kafka's strengths, including scalability, high throughput, fault tolerance, and real-time data processing.
| ✅ Advantages of Apache Kafka | ❌ Disadvantages of Apache Kafka |
|---|---|
| 1. Scalable and distributed architecture | 1. Complexity in setup and configuration |
| 2. High throughput and low latency | 2. Steeper learning curve for beginners |
| 3. Fault tolerance and high availability | 3. Requires dedicated hardware resources for optimal performance |
| 4. Durability and data replication | 4. Management and maintenance overhead |
| 5. Real-time data processing and streaming capabilities | 5. Lack of built-in security mechanisms |
| 6. Flexibility in data integration with various systems | 6. Limited built-in tooling for monitoring and management |
| 7. Horizontal scalability and handling of large data volumes | 7. Upgrades and version compatibility challenges |
| 8. Support for multiple programming languages and frameworks | 8. Relatively higher resource consumption compared to other tools |
📝 Real-World Use Cases
Kafka has become the go-to solution for real-time data streaming across various industries, including finance, healthcare, retail, and more. Kafka is used for a variety of use cases, including real-time analytics, log aggregation, event sourcing, and machine learning.
- Real-time Analytics: Kafka enables the processing and analysis of large volumes of streaming data, allowing organizations to derive real-time insights and make data-driven decisions.
- Log Aggregation: Kafka can collect logs from various systems and applications, making it easier to centralize and analyze log data for monitoring, troubleshooting, and auditing purposes.
- Event Sourcing: Kafka's distributed architecture and fault tolerance make it suitable for event sourcing patterns, where events are stored as a source of truth and can be replayed for building event-driven systems.
- Messaging System: Kafka serves as a reliable and scalable messaging system, facilitating communication between different microservices or distributed systems.
😎 Conclusion
Apache Kafka has become the preferred option for real-time data streaming across various industries. Its distributed nature, scalability, fault-tolerance, and speed make it an ideal solution for streaming applications. If you're looking for a solution to handle massive volumes of data in real-time, Apache Kafka is the way to go.


FAQs
Is Apache Kafka only used for real-time data processing?
No, Apache Kafka can be used for various purposes, including log aggregation, event sourcing, and messaging systems.
What programming languages are supported by Kafka?
Kafka provides client APIs for several programming languages, including Java, Python, C/C++, and .NET.
Can Kafka handle large data volumes?
Yes, Kafka's distributed architecture and scalability make it capable of handling large data volumes efficiently.
Is Apache Kafka suitable for small-scale applications?
While Kafka is designed to handle high-throughput scenarios, it can also be used in smaller-scale applications where real-time data processing is required.
How does Apache Kafka ensure high availability and fault tolerance?
Apache Kafka ensures high availability and fault tolerance through its replication mechanism. Data is replicated across multiple brokers, ensuring that if one broker fails, data remains accessible from other replicas.
Can Apache Kafka handle large-scale data streaming?
Yes, Kafka can handle large-scale data streaming. It is designed to be scalable and can be easily scaled horizontally to handle more data. Kafka also uses a distributed architecture to improve performance.
What is the role of Apache ZooKeeper in Kafka's performance?
Apache ZooKeeper plays a crucial role in Kafka's performance by managing the Kafka cluster, storing metadata, and coordinating tasks like leader election and synchronization between brokers.
Are there any alternatives to Apache Kafka for real-time data processing?
Yes, there are alternative solutions to Apache Kafka for real-time data processing, such as Apache Pulsar, RabbitMQ, and AWS Kinesis, Google Cloud Pub/Sub, IBM MQ and Microsoft Azure Event Hubs.