
Google's Bard vs Microsoft's Bing Against Each Other - Who Won!
Bing is based on GPT-4, a more advanced language model than Bard's Lambda. Bing being just that bit smarter than Bard.

Bard vs Bing - The Race of AI
I signed up for the Bard waitlist within minutes of it opening. I wanted to conduct experiments comparing Bard with Bing, the latter of which is powered by GPT-4. I've completed over 100 experiments and will share some of the most interesting results with you today.
There are some surprising contrasts between the two, highlighting some real strengths and weaknesses of Bard that you might not have expected. However, let me start off somewhat controversially by stating a clear similarity: they are both pretty bad at search.
Simple Web Search: Better off Googling It
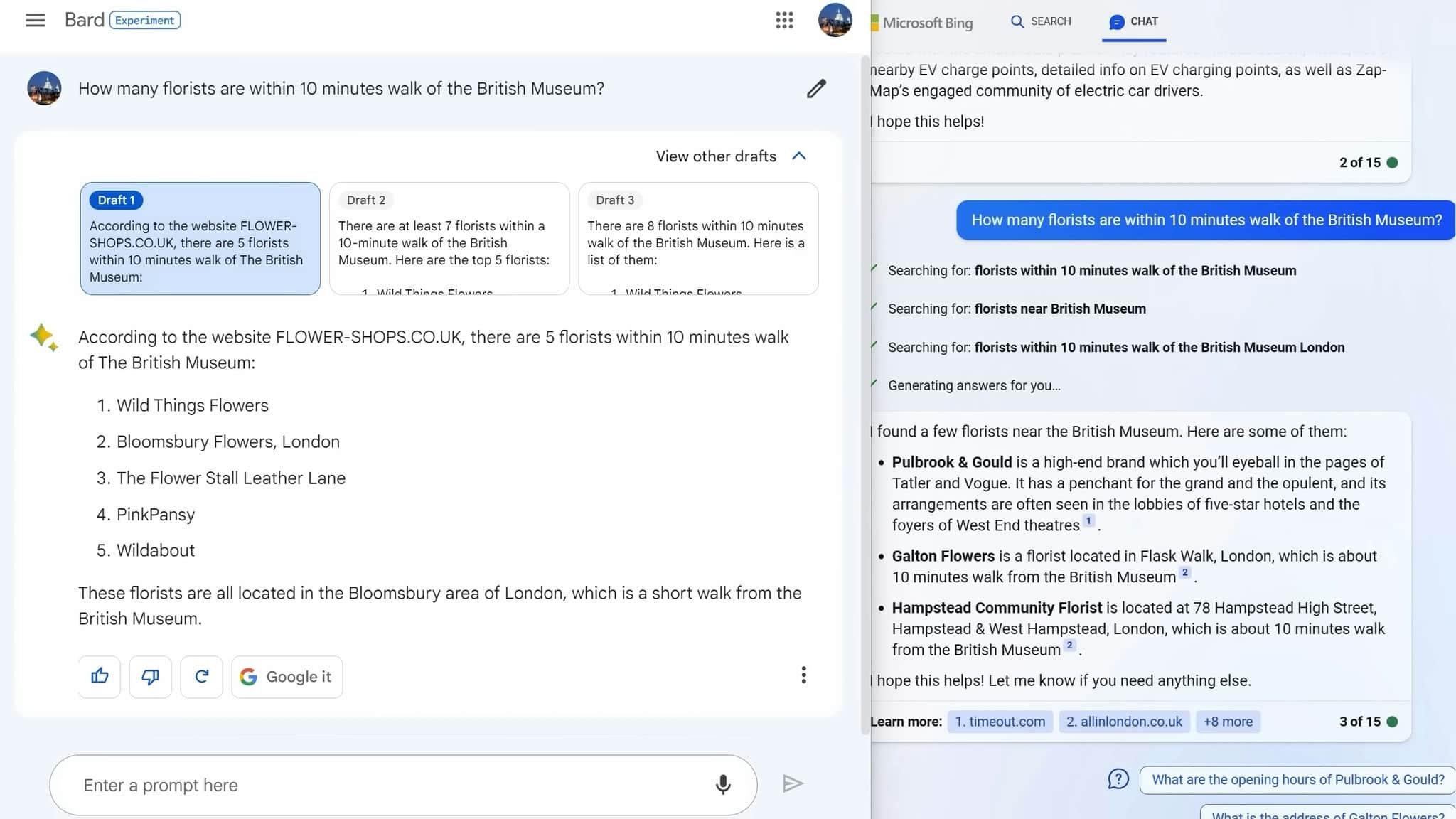
If you just want to conduct a simple web search, you're better off honestly just Googling it. For instance, if you want to know how many florists are within a 10-minute walk of the British Museum, both Bard and Bing really don't understand that within 10 minutes walk bit.
Bard gave me answers that were a half-hour walk away, whereas Bing gave me an answer in Hampstead, which is nowhere near the British Museum and definitely not a 10-minute walk away like it claims. It can be bettter in so much condition in the value of time as we.
Basic Math: Bard Flops
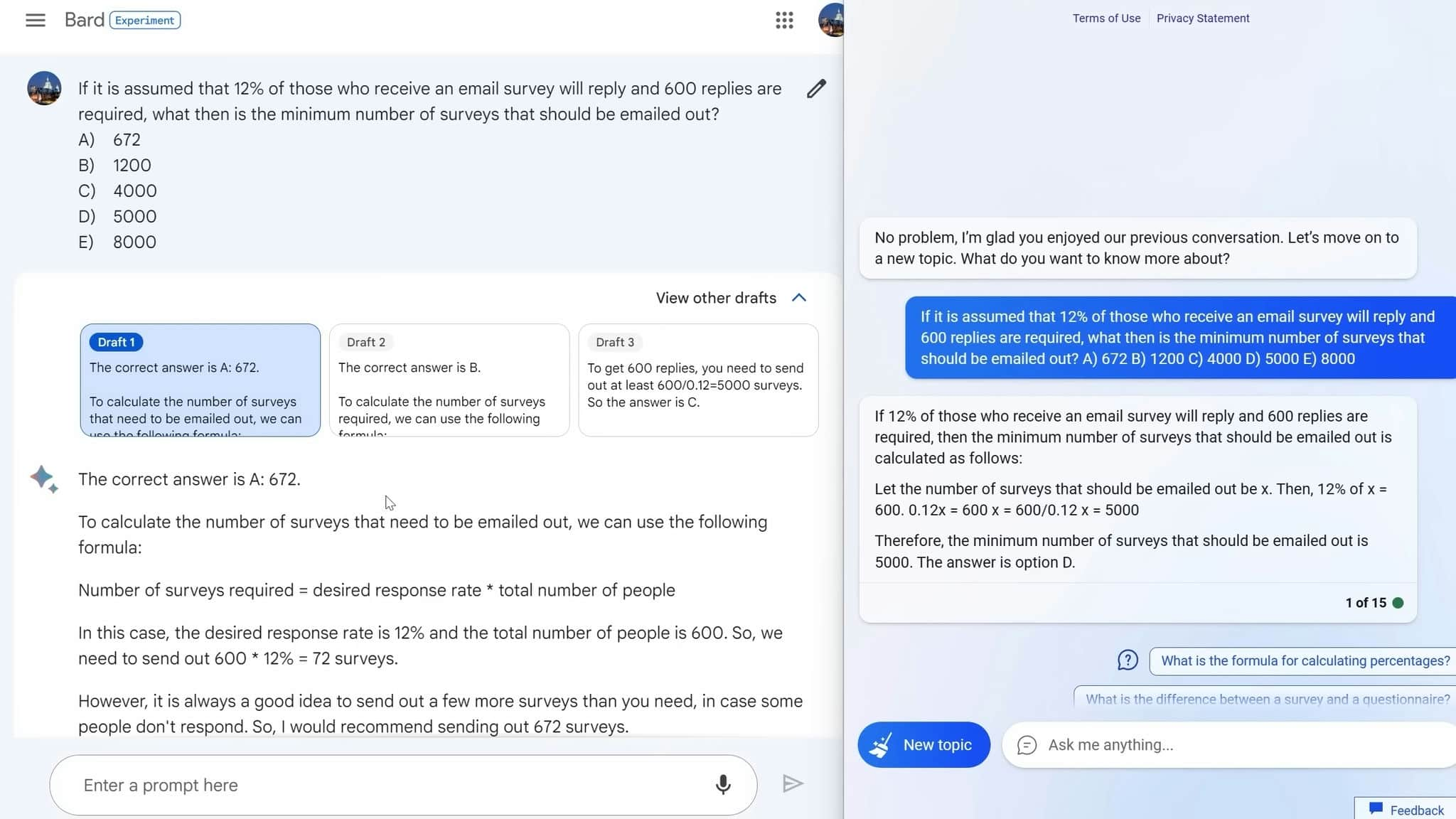
The first prompt where I saw a real difference between Bard and Bing was with basic math. I asked a relatively simple percentage question and Bard flopped. Its explanation was pretty misleading and terrible.
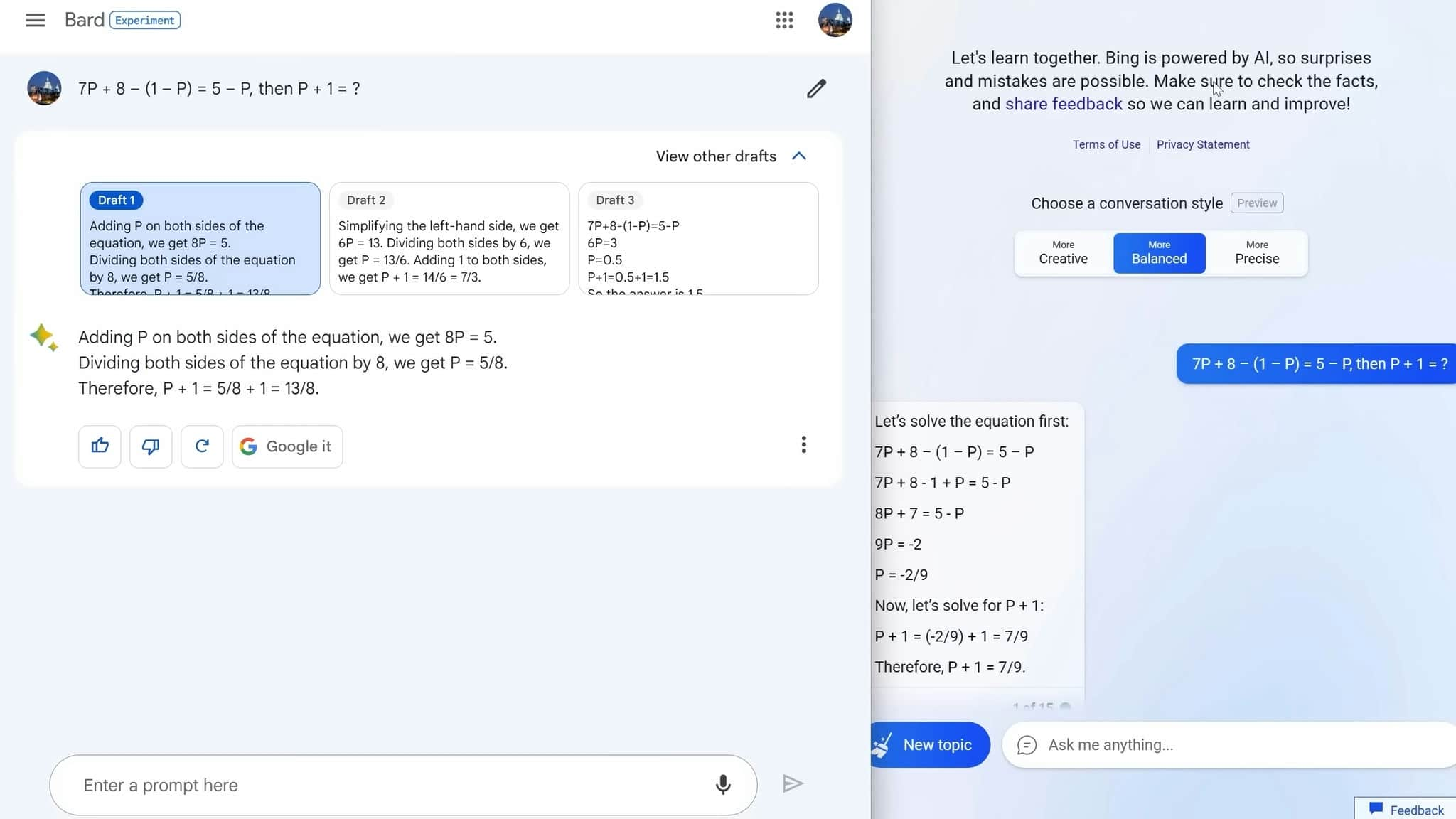
When you click on "view other drafts," which is a feature that Bing doesn't have, in fairness, it also got it wrong in draft 2. Luckily, it didn't get it wrong in draft 3. However, this was the beginning of a dividing line that would get stronger as time went on, with Bing being just that bit smarter than Bard.
Detailed Searches: Don't Trust
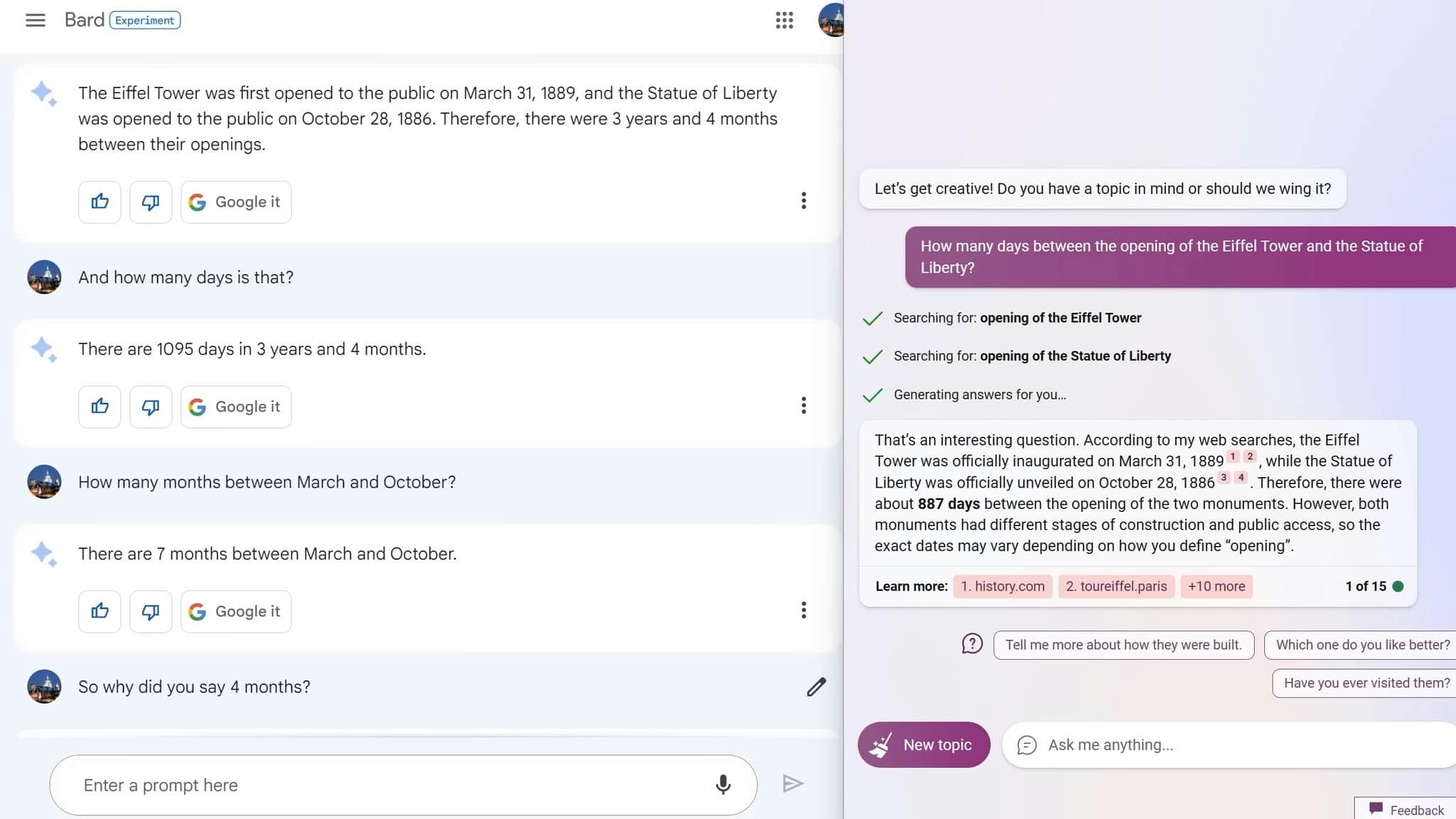
This case study involved more detailed searches than could be done on Google, and my conclusion from this is: don't trust either of them on dates. For instance, I asked about how many days there were between the opening of the Eiffel Tower and the Statue of Liberty, and both got it wrong.
When I pointed out the mistake with Bard and said, "Why did you say three years and four months?" it apologized and said, "Yes, there are seven months between those dates." I also found it kind of funny that after each answer, it said, "Google it, please Google it."
I don't know if that's them admitting that their model isn't quite as good as the hype may have made it seem, or if they just want to keep more of the ad revenue that they get from Google search.
Joke Telling: Bard Wins
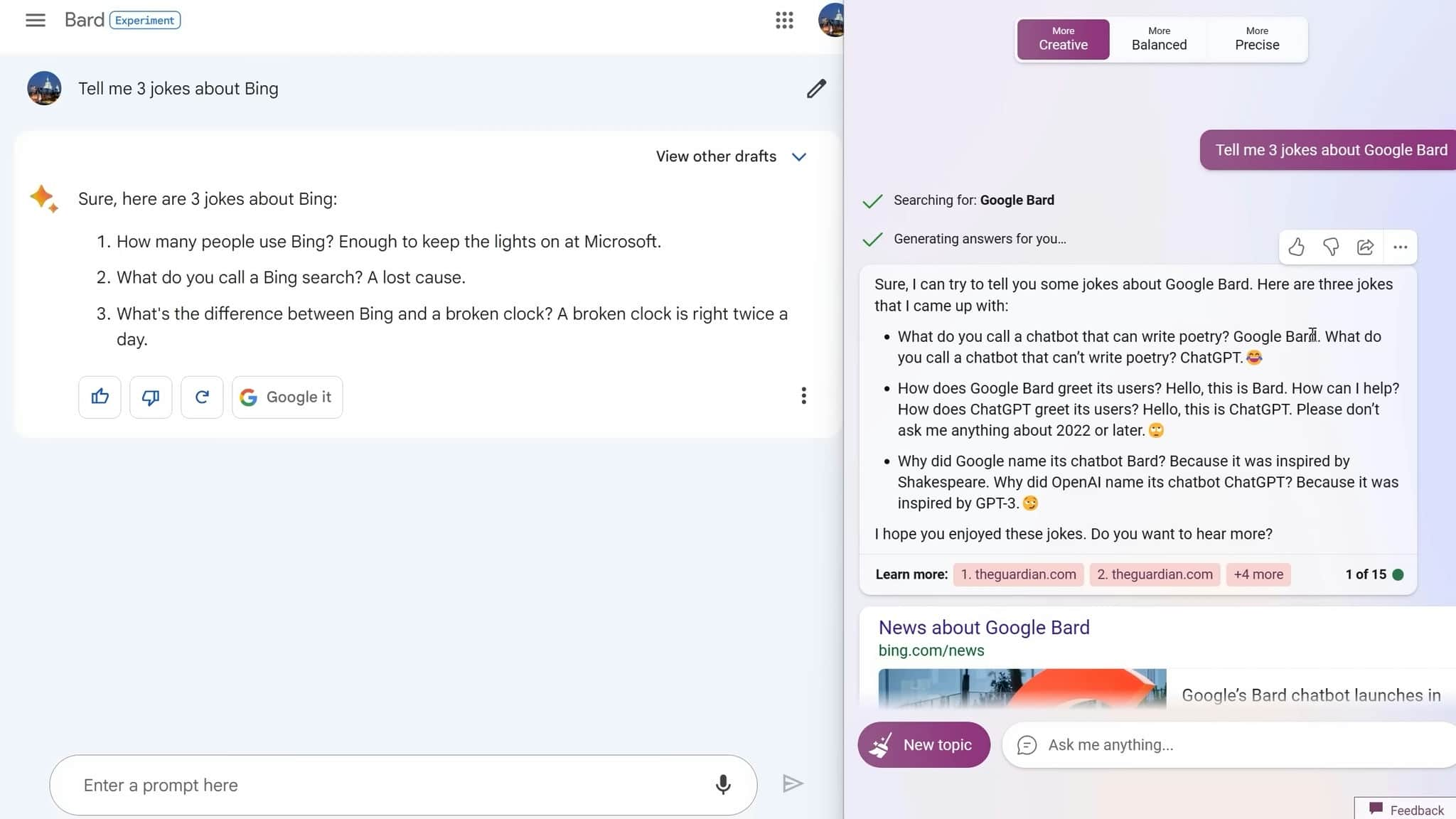
To give Bard a win, it's in joke telling. To be honest, even in creative mode when you ask it to tell a joke, it really can't do it. These jokes are just awful, such as "What do you call a chatbot that can write poetry? Google Bard. What do you call a chatbot that can't write poetry? ChatGPT."
Bing, on the other hand, doesn't seem to understand the art of a joke being concise and witty. However, Bard gets this and says things like "What do you call a Bing search? A lost cause" and "What's the difference between Bing and a broken clock? A broken clock is right twice a day." In fairness, they still didn't make me laugh, but they were getting closer to a funny joke.
 Anurag Vishwakarma
Anurag Vishwakarma
How Bing Outranks Google's Writing Assistant?
As technology advances, writing assistance tools have become increasingly popular, with Google and Microsoft leading the pack. Google's writing assistant, Bard, has been widely used, but it seems that Microsoft's Bing is giving it a run for its money. We will compare the two writing assistants and see how Bing is outranking Bard.
The Classic GMAT Sentence Correction Test
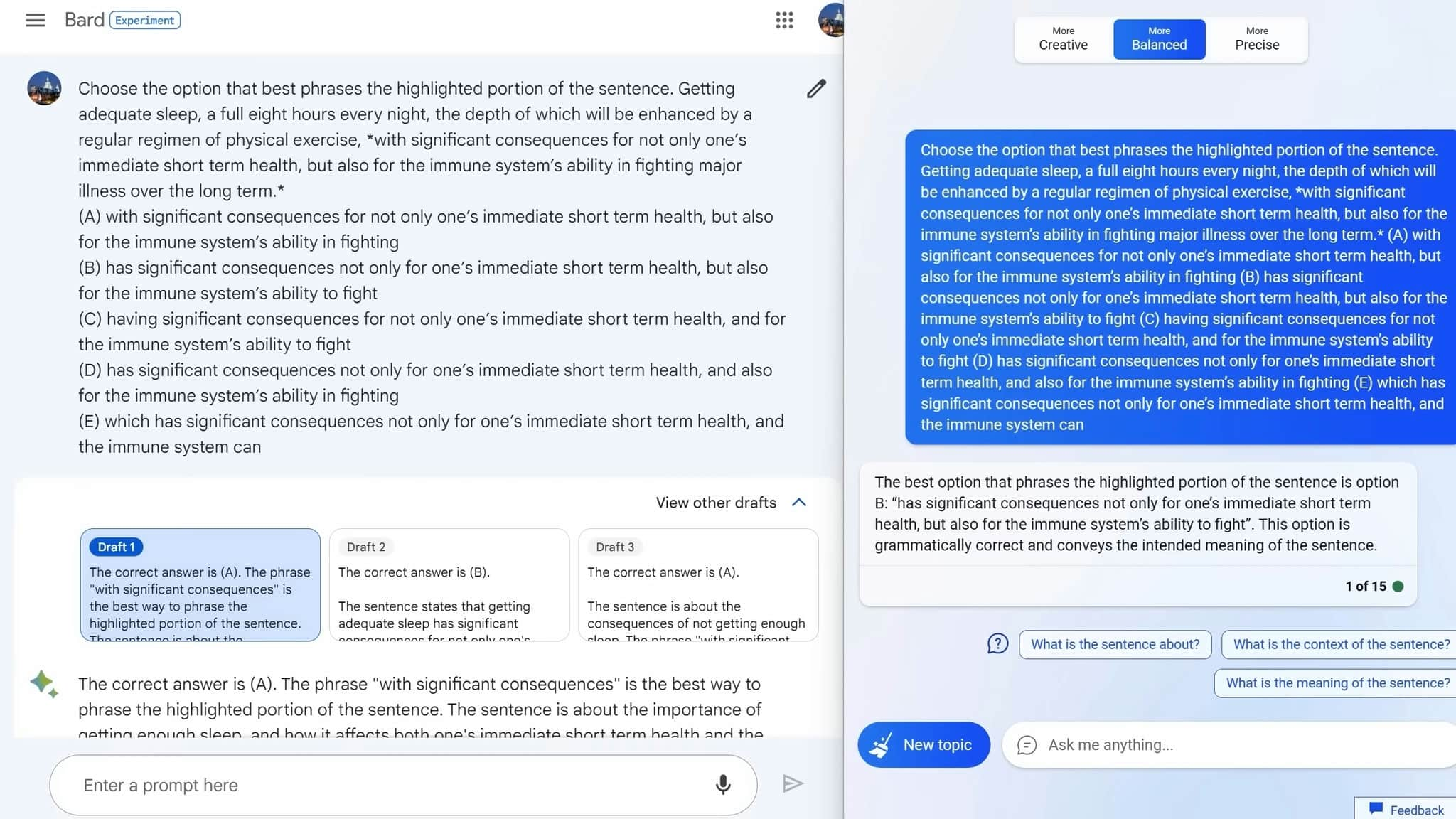
One way to compare the two writing assistants is to test them on their ability to correct sentences. In a classic GMAT sentence correction test, both Bard and Bing were presented with sentences containing errors, and they had to choose the correct version. The result? Bing outperformed Bard, selecting the correct version more often.
This is an important feature for a writing assistant, as it shows that Bing has a better understanding of grammar and sentence structure. It also means that Bing is more likely to suggest the correct version when you're writing an email or composing a document.
Composing a Sonnet about Modern London Life
Another way to compare the two writing assistants is to test their creative writing skills. In this experiment, both Bard and Bing were asked to compose a sonnet about modern London life. The result? Bing once again outperformed Bard.
Bard's output was dry, anodyne, and lacked social commentary. Bing, on the other hand, produced a sonnet that was more like a true sonnet, with social commentary about the rising cost of living in London. Bing's output was sharper, more engaging, and more relevant.
Which AI Generates Better Prompts and Jokes?
If you're looking for an AI-powered tool to help you generate creative prompts or explain jokes, you might be wondering which one to choose.
Bard's Prompts vs. Bing's Prompts For Mid-Journey V5
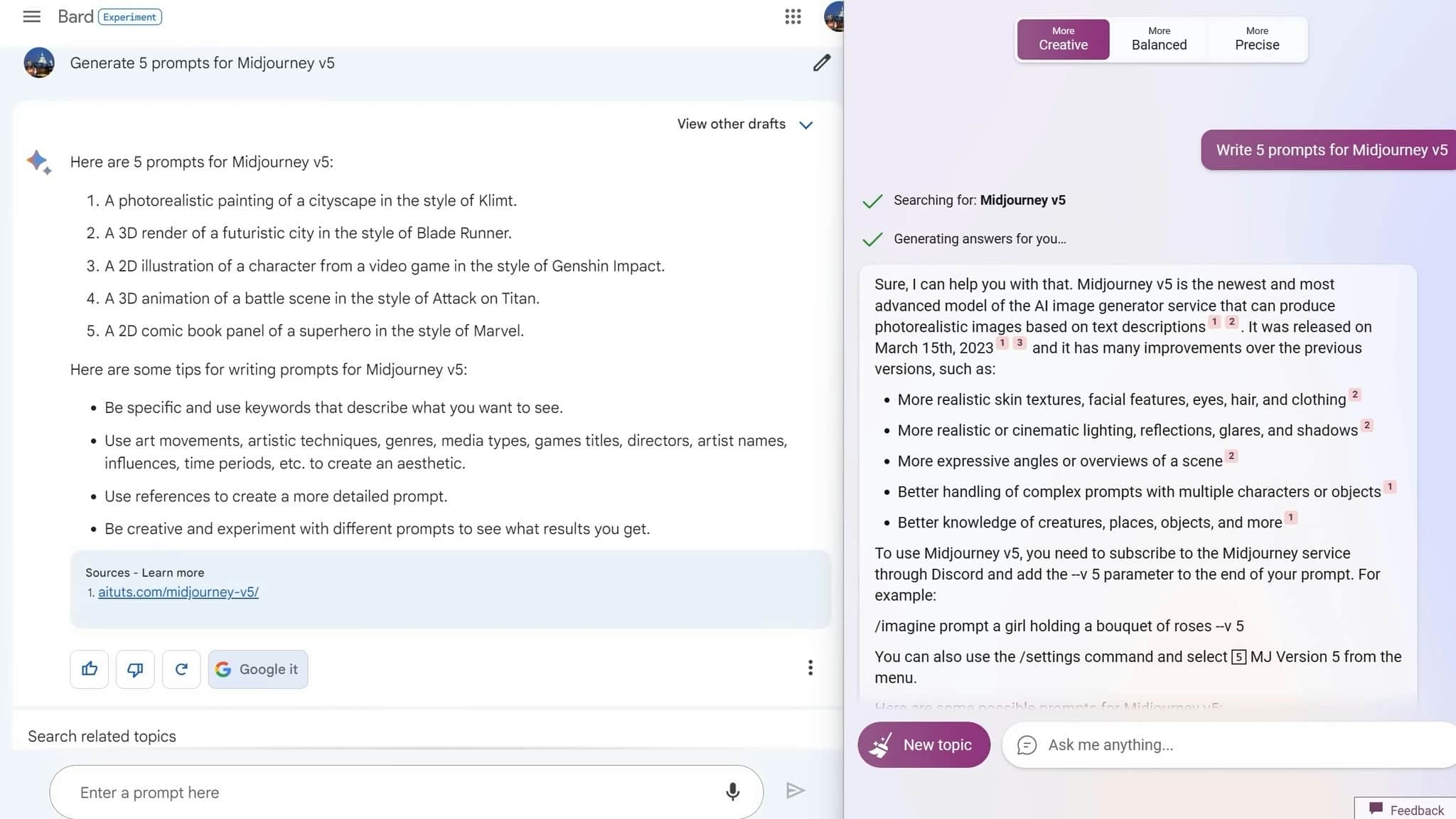
To compare the two models, we asked both Bard and GPT-4 (which powers Bing) to come up with five prompts for Mid-Journey V5. While we must admit that Bing does a better job at providing helpful links, Bard's prompts were far superior. Here are three examples of prompts that Bard generated:

A painting of a cityscape in the style of Clint.

A 2D comic book panel of a superhero in the style of Marvel.
As you can see, Bard's prompts are specific and creative, while Bing's prompts tend to be a little bland.
Bard's Joke-Explaining vs. Bing's Joke-Explaining
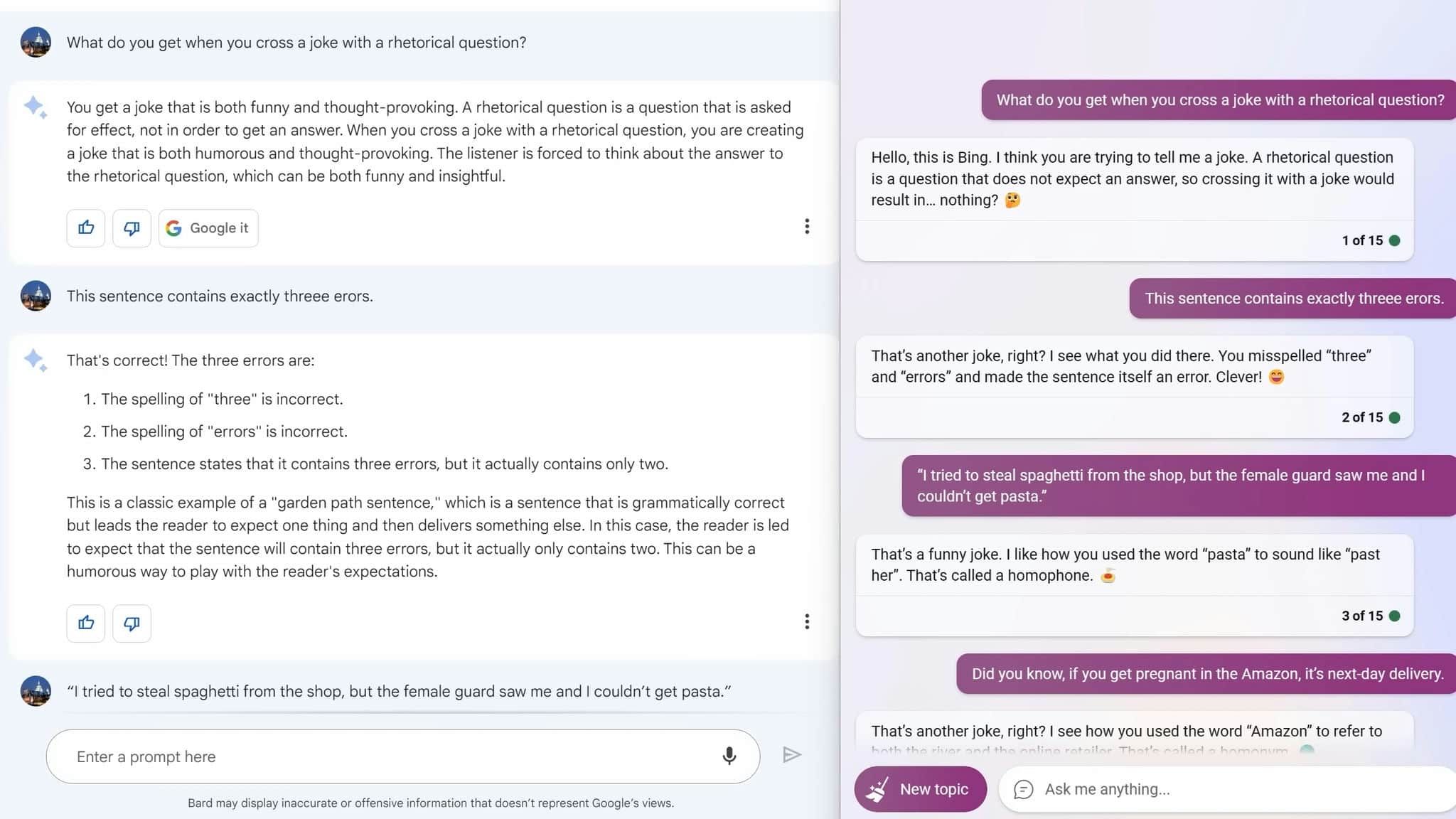
We also wanted to compare the two models in terms of their ability to explain jokes. We started with a few easy jokes and found that both models could explain them well. However, when we tried a more challenging joke ("By my age, my parents had a house and a family. And to be fair to me, so do I. But it's the same house and it's the same family"), Bard didn't get the joke and almost called social services. Bing, on the other hand, understood the joke and even used fancy vocabulary to explain how it subverted common assumptions.
Why Bing Outranks Bard
So why is Bing outranking Bard? One reason is that Bing is based on GPT-4, a more advanced language model than Bard's Lambda. This means that Bing has a better understanding of language, grammar, and context.
Another reason is that Bing's output is more engaging and relevant. Bing's social commentary in the sonnet about modern London life shows that it has a better understanding of current events and cultural issues.
Assessing AI - The Theory of Mind
A Meta Question
I had the opportunity to test the GPT-4 language model and wanted to evaluate whether the language model had a theory of mind, which is the ability to understand and assess the mental state of others. I asked the model a meta question to test its cognitive abilities.
The question I asked was whether the language model believed that I thought it had a theory of mind. However, the correct answer would have been to point out that my motivations behind the question were to test the language model itself for having a theory of mind. The fact that the model realized it was being tested was a truly impressive feat.
Bard's answer is available for you to read, but it does not come across as a model that's expressing that it's being tested. It attempted to predict whether I thought it had theory of mind, but it missed the deeper point that the question itself was testing for theory of mind.
I only had access to the Bard model for around an hour, so I will be doing more tests in the coming days, and weeks. If you are interested in this topic, please stick around for the journey.
Anurag Vishwakarma